
In this article
Introduction
When a random experiment is performed, its outcome does not depend upon the previous and future outcomes of the experiment, therefore these outcomes of the random experiment are known as the random variables.
These outcomes can be defined for the discrete data (having a specific value) and/or continuous data (having values in a defined interval) and are therefore called discrete random variables and/or continuous random variables, respectively. This article will discuss the uses, applications, and types of random variables.
Definition and Explanation of the random variables
The random variable is defined as the outcome of a random experiment or a random phenomenon, which does not relate to the outcome of the previous or future outcomes of any experiment. The random variables are also called stochastic variables since a random experiment is also known as a stochastic experiment. The random variables can possess any real value in contrast to the algebraic variables which can have only selective values depending on the conditions defined by the algebraic equations.
For example, in an experiment related to rolling three dice at the same time the sum of numbers that appears on the top of the dice, the smallest and the largest values can be, 1+1+1 = 3, and 6+6+6=18, respectively. Therefore, if we note down the sum of numbers that appeared on rolling the dice will take the values between 3 to 18. The obtained values can be utilised to define the probability distribution function of the random variables.
Types of Random Variables
The random variables in a broad overview can be defined in two ways, such that,
- Discrete random variables
- Continuous random variables
Discrete Random Variables
The random variables that can choose definite/finite values are called discrete random variables. For example, the number of students in the schools, the number of buses at bus stations, the number of trains running between two stations, etc. Therefore, a probability distribution can be defined for them which determines the probability to choose that definite value in the distribution of the random variables. The very known types of discrete random variables are the Bernoulli random variables, Poisson random variables, Geometric random variables, etc.
Continuous random variables
The random variable that can take any value from a defined interval is called the continuous random variable. For example, the height of the men in India, the weight of the people in a town, etc. The probability of obtaining a continuous random variable is zero, since determining the exact value of the random variable in continuous random variable distribution is zero, therefore, a probability density function is defined. The known continuous random variable distributions are exponential random variables, normal random variables, etc.
Mean and Standard Deviation of Random Experiment
Mean of the Random Experiment
The average value of the distribution of the random variables is called the mean of the random variables. Interestingly, the mean of the random variables is also called the expected value of the random variable. If we define the random variable, 
The mean of the discrete random experiment can be defined as,
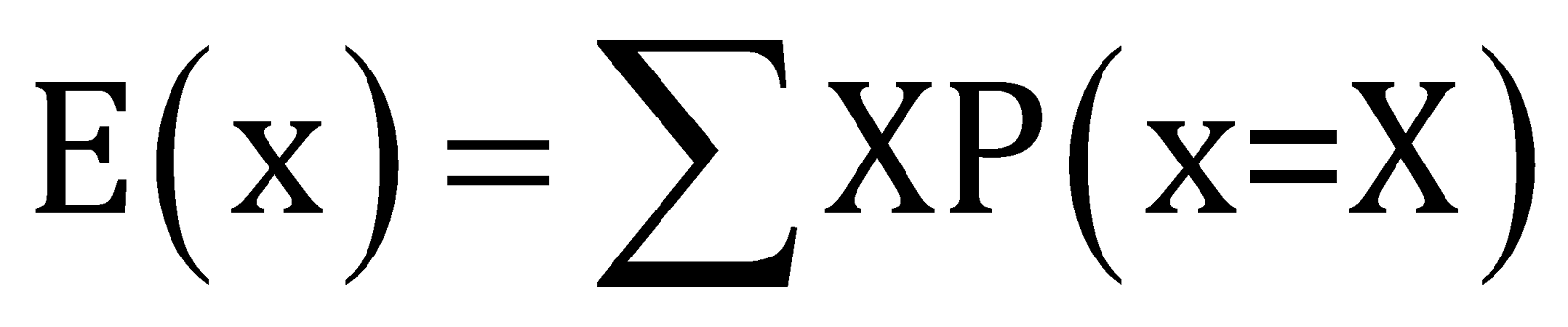
Where 
The mean of the continuous random experiment can be defined as,
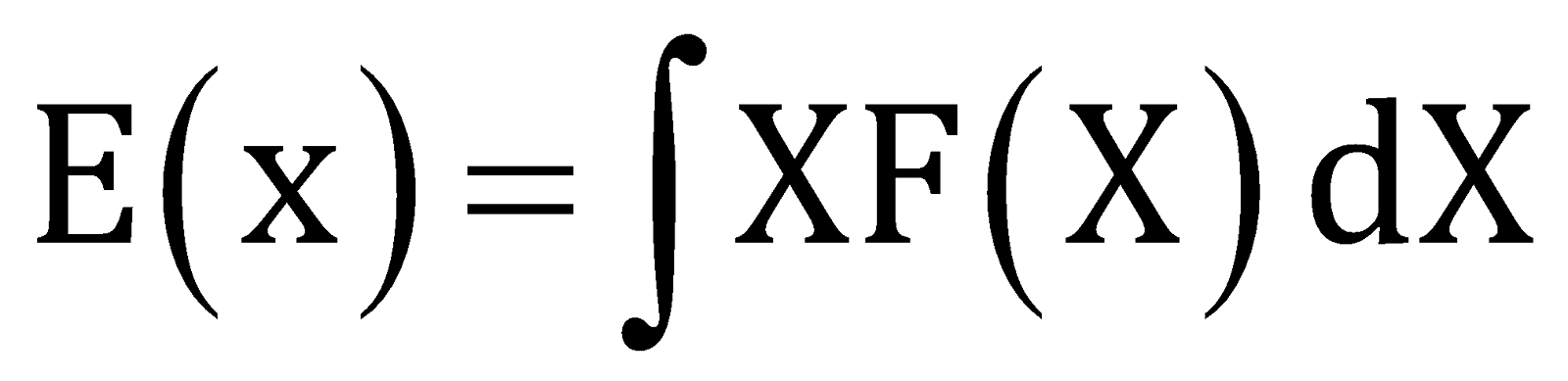
Where
The standard deviation of the Random Experiment
When a random experiment has been performed the outcomes of the random experiment are deviated from the mean or expected values, therefore the square root of the sum of the square of the deviation of the random variables from the mean position is defined as the standard deviation of the random experiment.
The standard deviation of the discrete random experiment can be defined as,
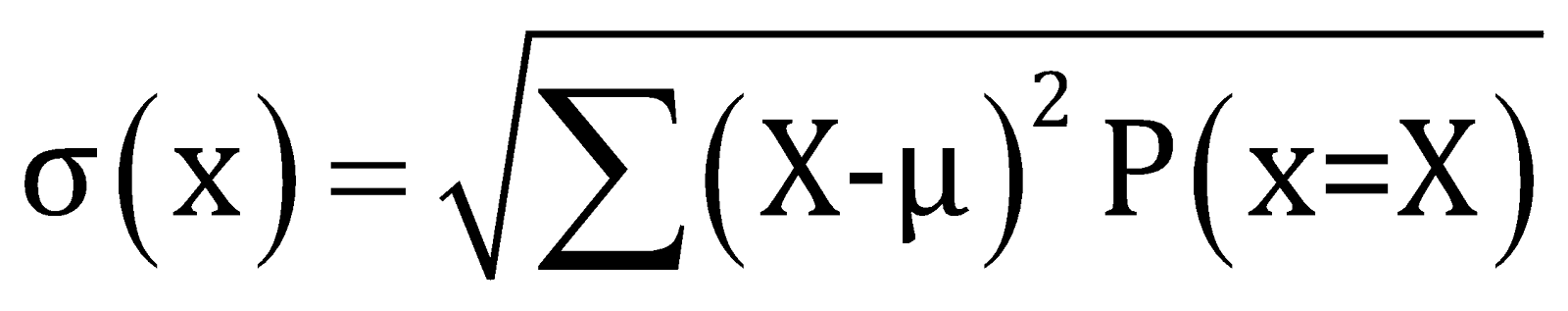
Where
The mean of the continuous random experiment can be defined as,
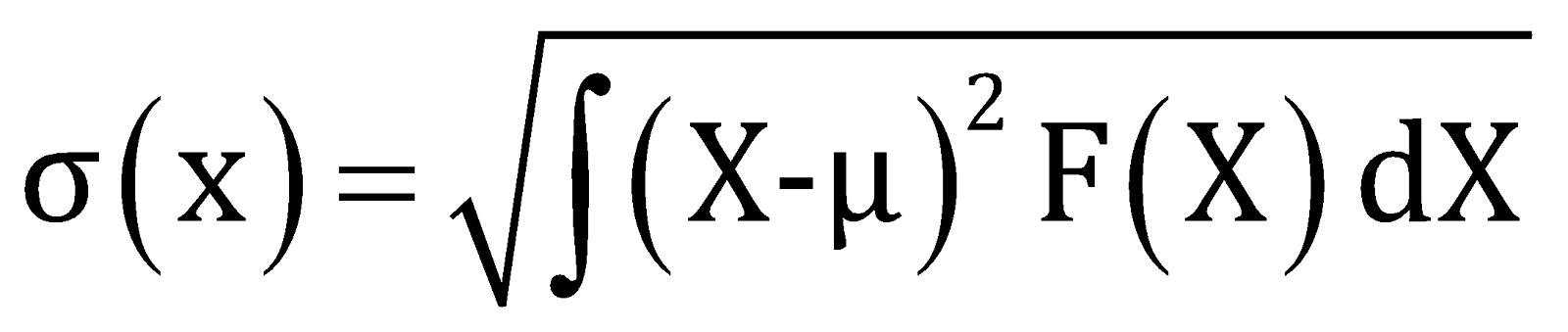
Where
Transforming Random Variables
In the process of transforming the random variables one performs the different mathematical operations on the given data set and then investigates the effect of these operations on the outcome of the given data set. The different types of these mathematical operations include adding or subtracting a constant from the random variable, multiplying or dividing the random variable with a contact factor, adding or subtracting the two random variables, etc.
Effect of transforming a random variable on the outcome of the dataset
If we have a random variable 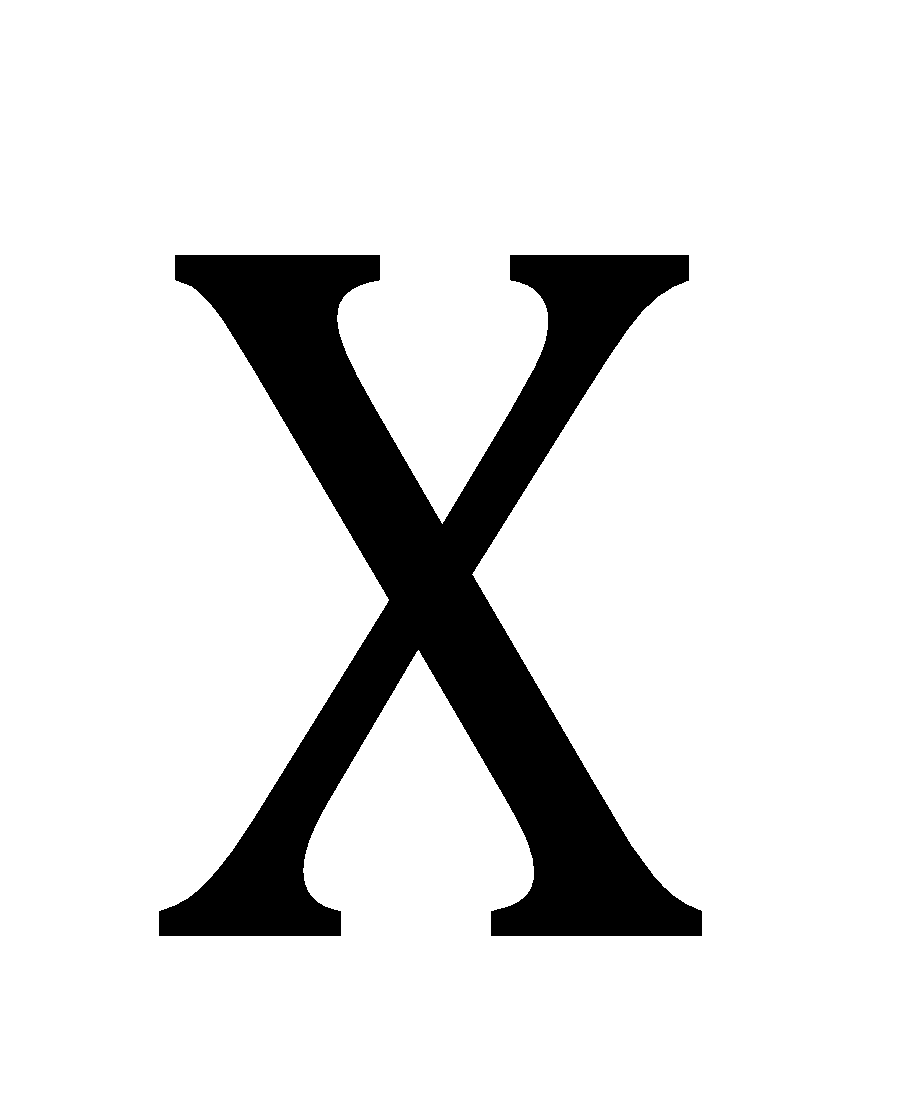
Adding or subtracting a constant to the data
After adding or subtracting the constant

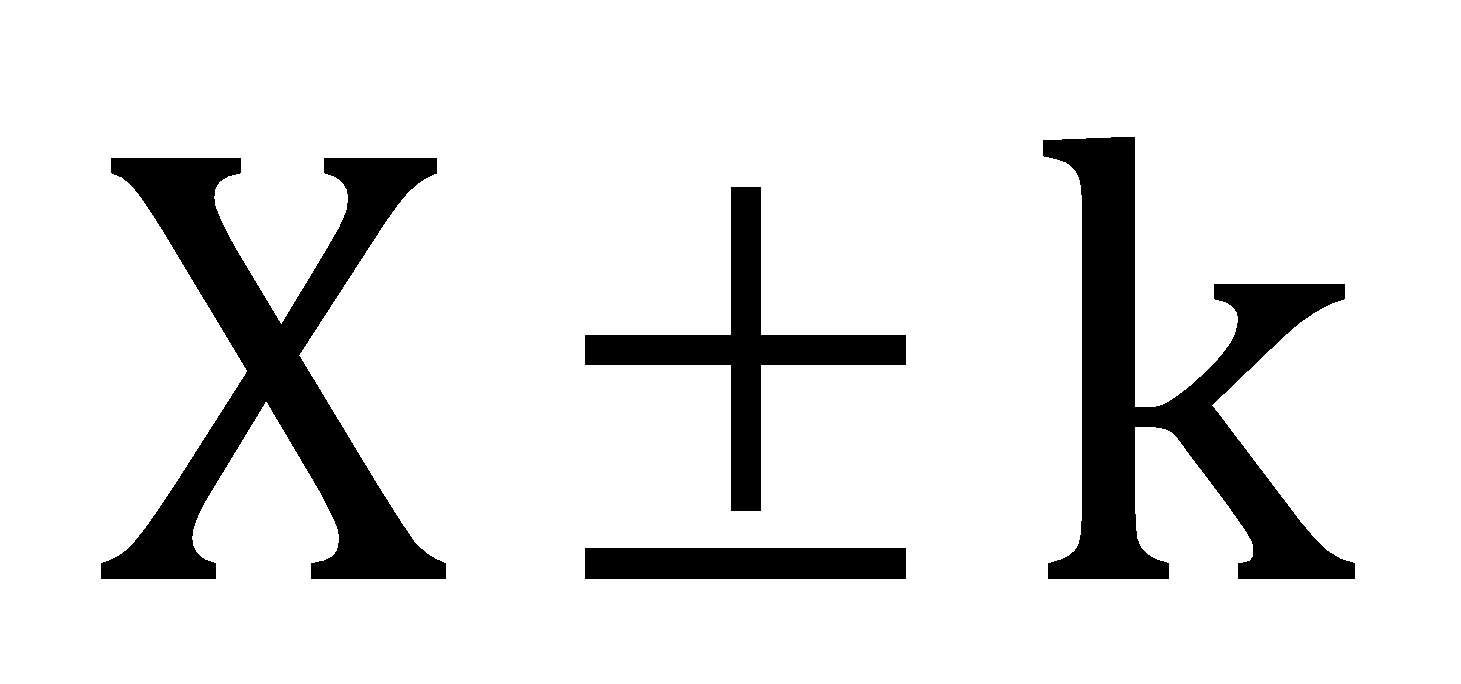
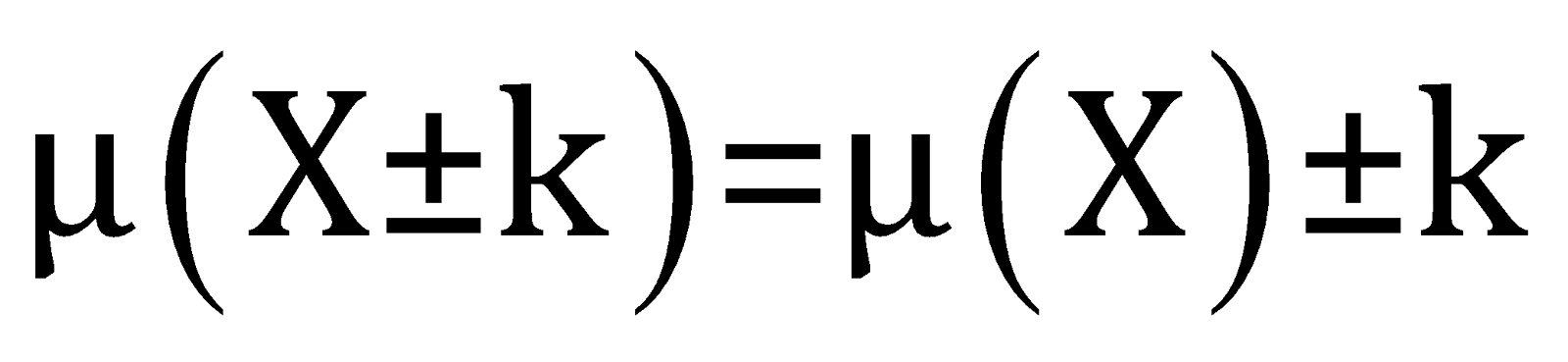
The standard deviation of the new dataset
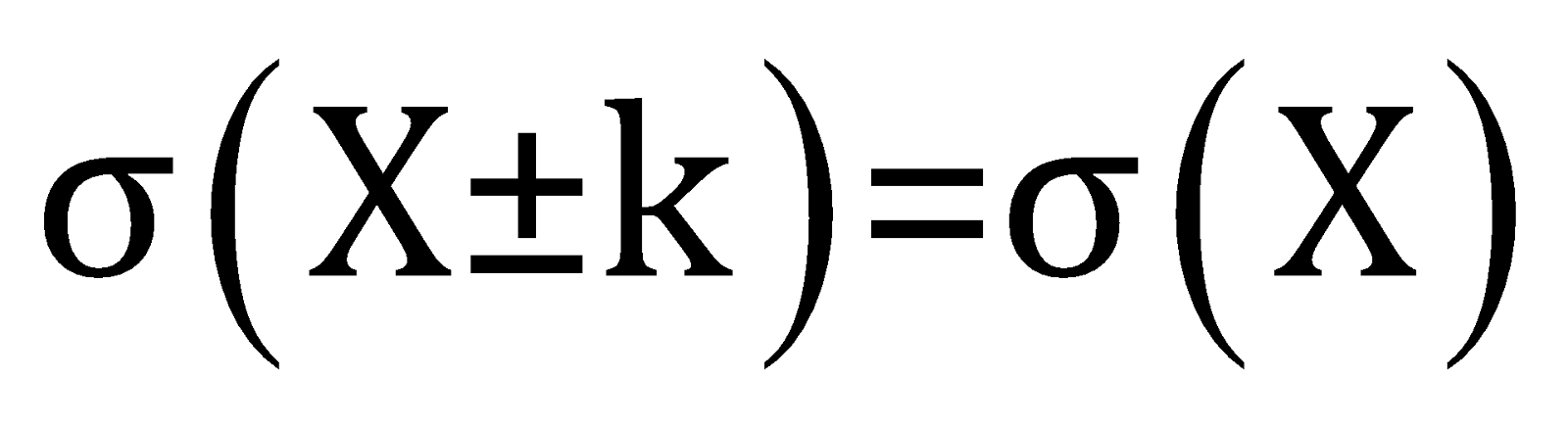
Multiplying a constant to the data
After multiplying a constant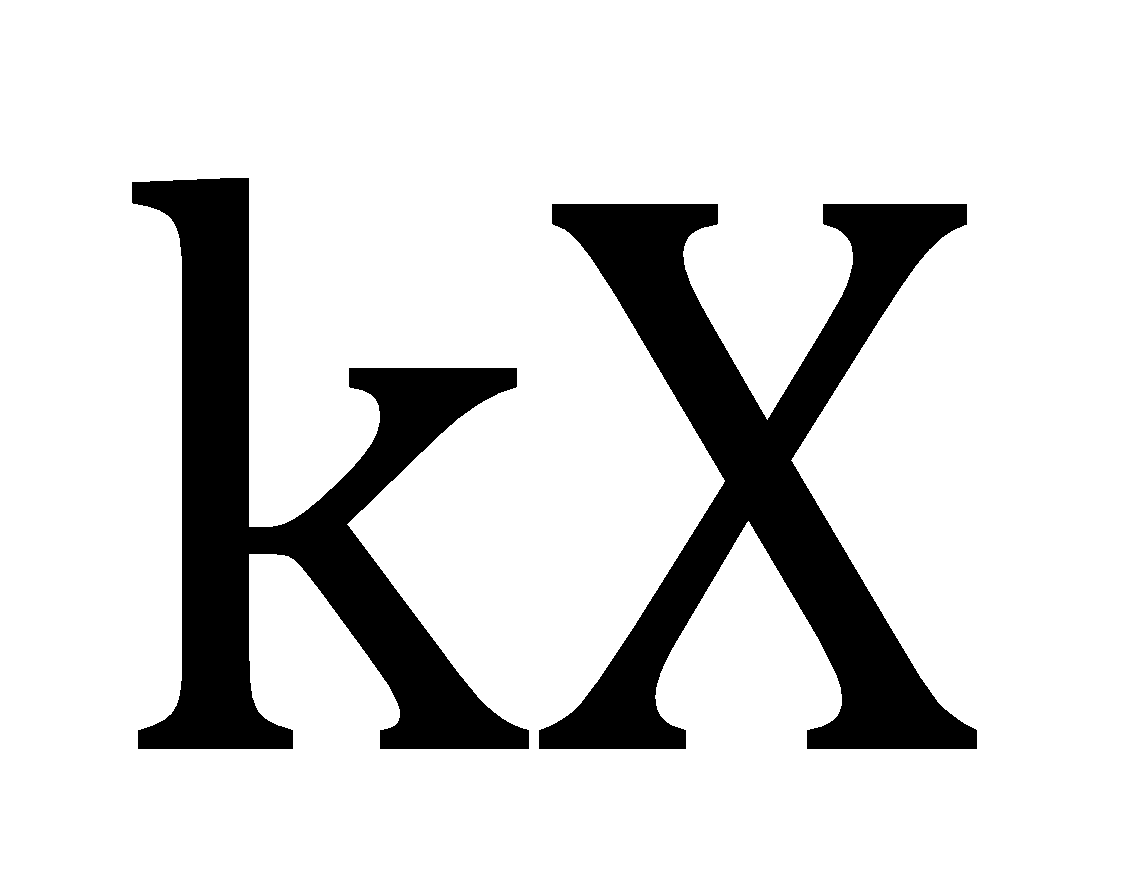
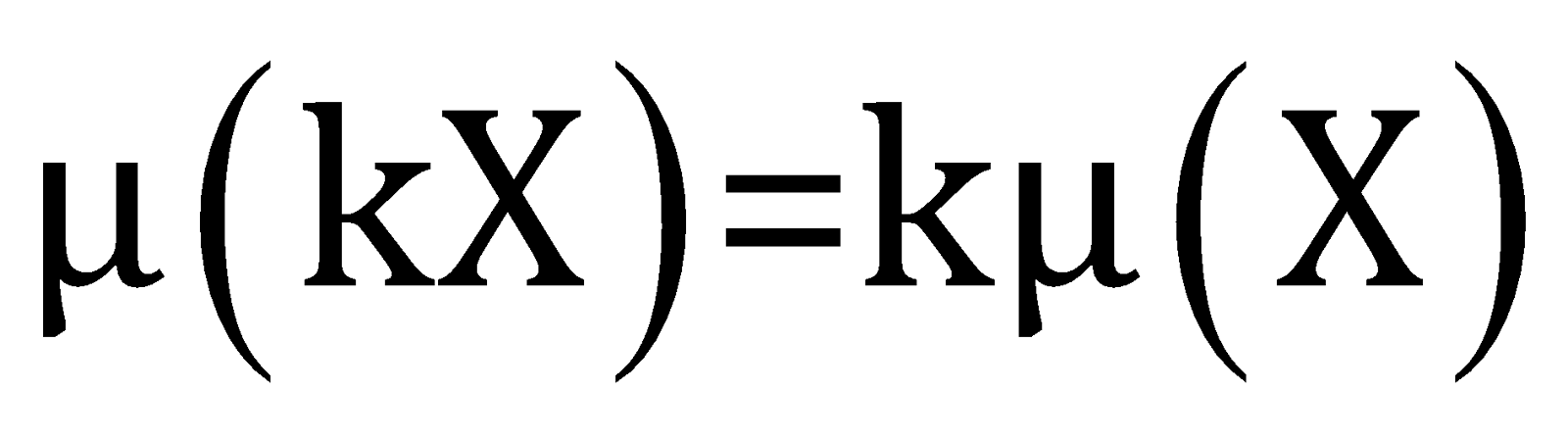
The standard deviation of the new dataset 
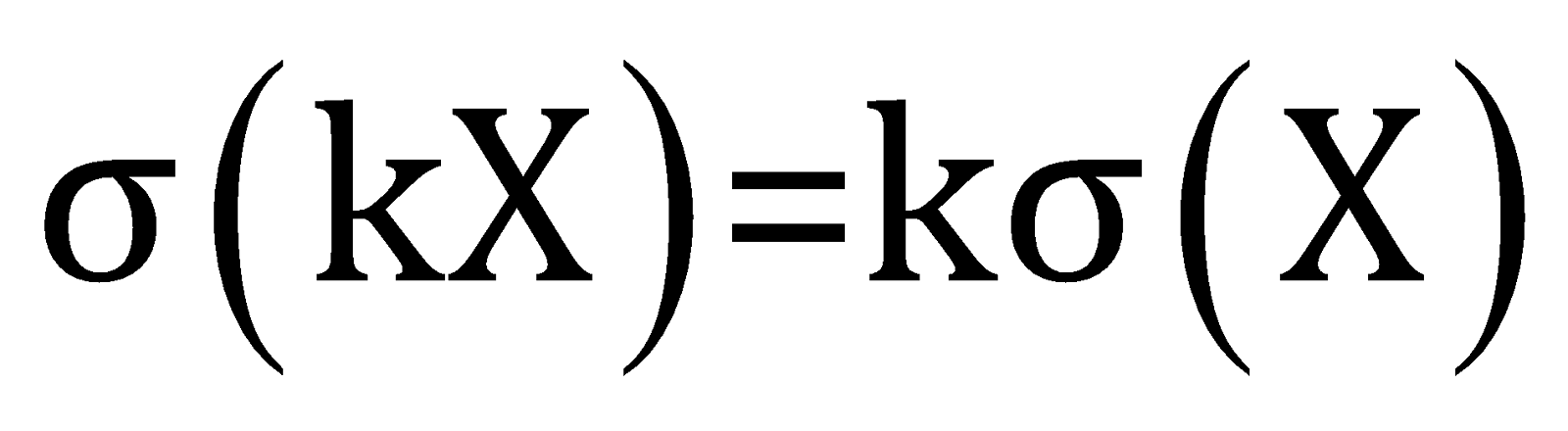
Dividing a constant to the data
After dividing a constant
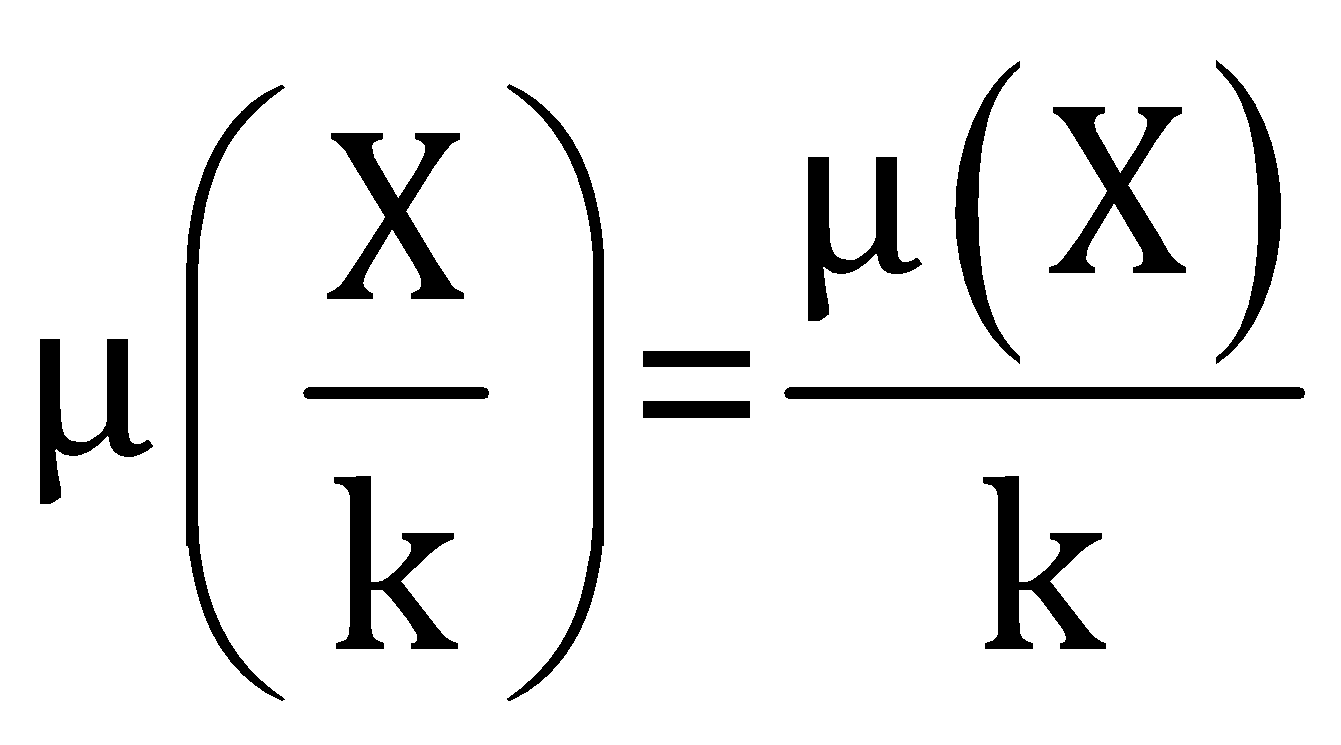
The standard deviation of the new dataset can be given by the relation,
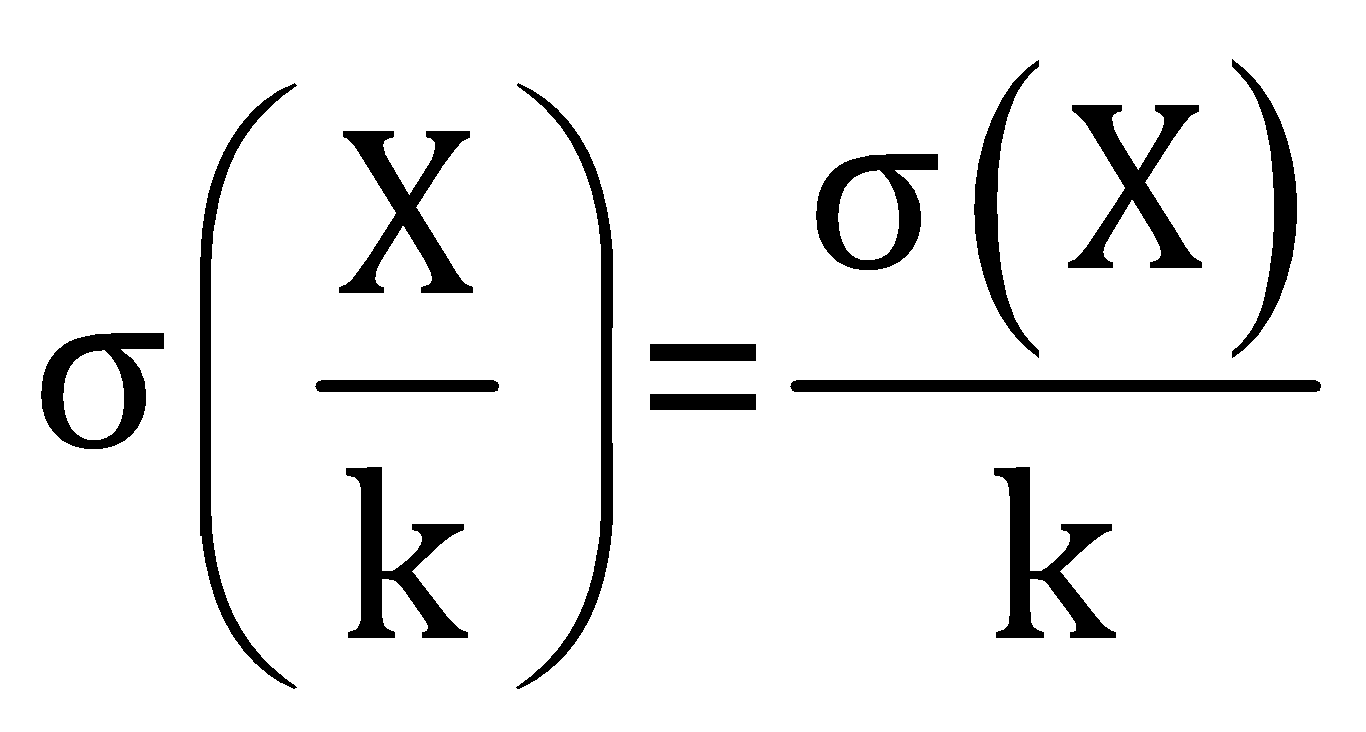
Combining Random Variables
The combination of the random variables means that two or more random variables are combined to transform into another new random variable. Therefore, if there are two random variables , which are defined in the given sample space of , such that,
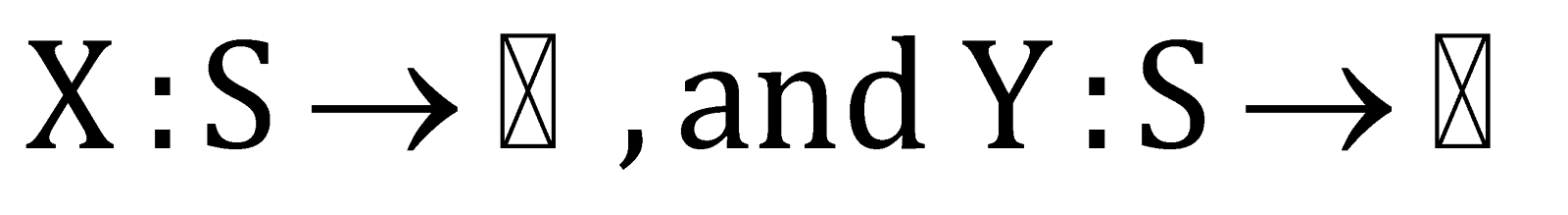
Then we can perform the normal operations to these random variables to give a new type of random variable, such that,
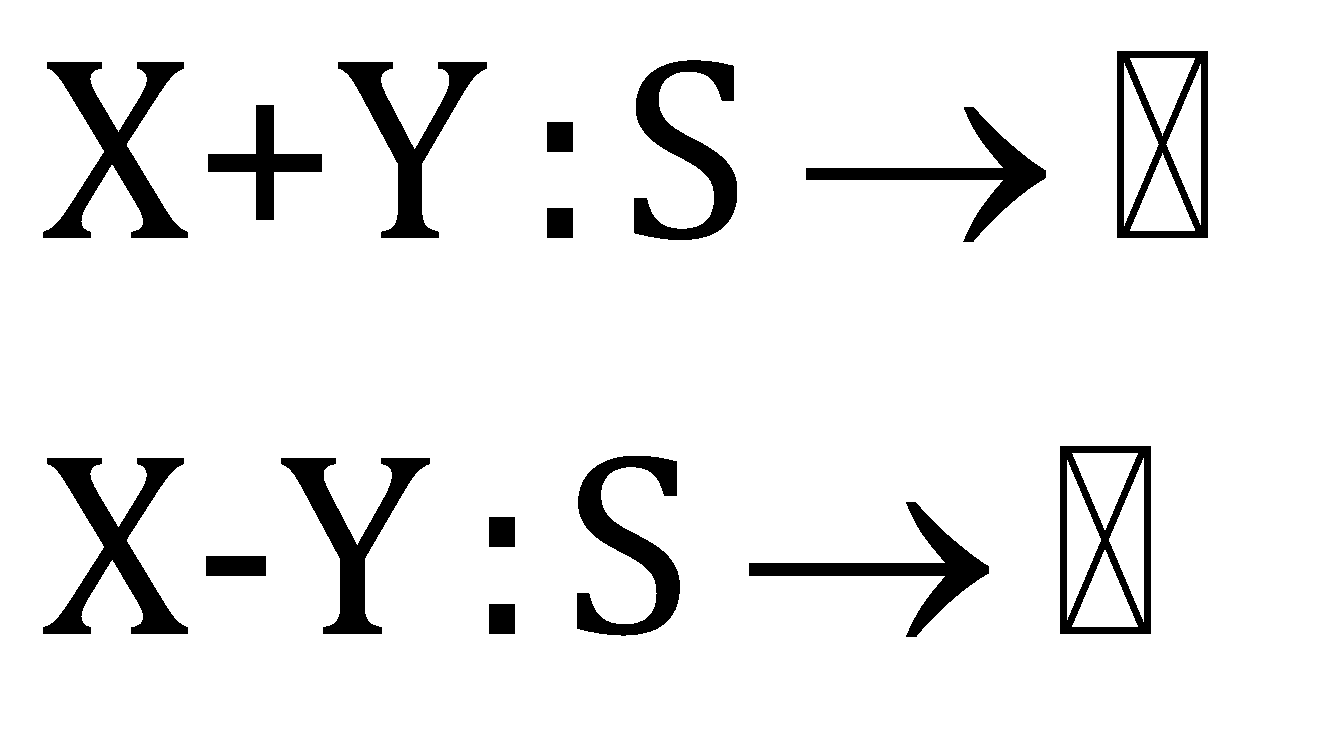
Therefore, the sum or difference of the random variables gives the new type of random variables.
Mean and Variance of Sum and Difference of Random
For the given variables , if the expectation/mean values are , respectively, and standard deviations are , respectively. Then we can define a relation of the mean and standard deviation of the combined variables such that,
For the new random variable 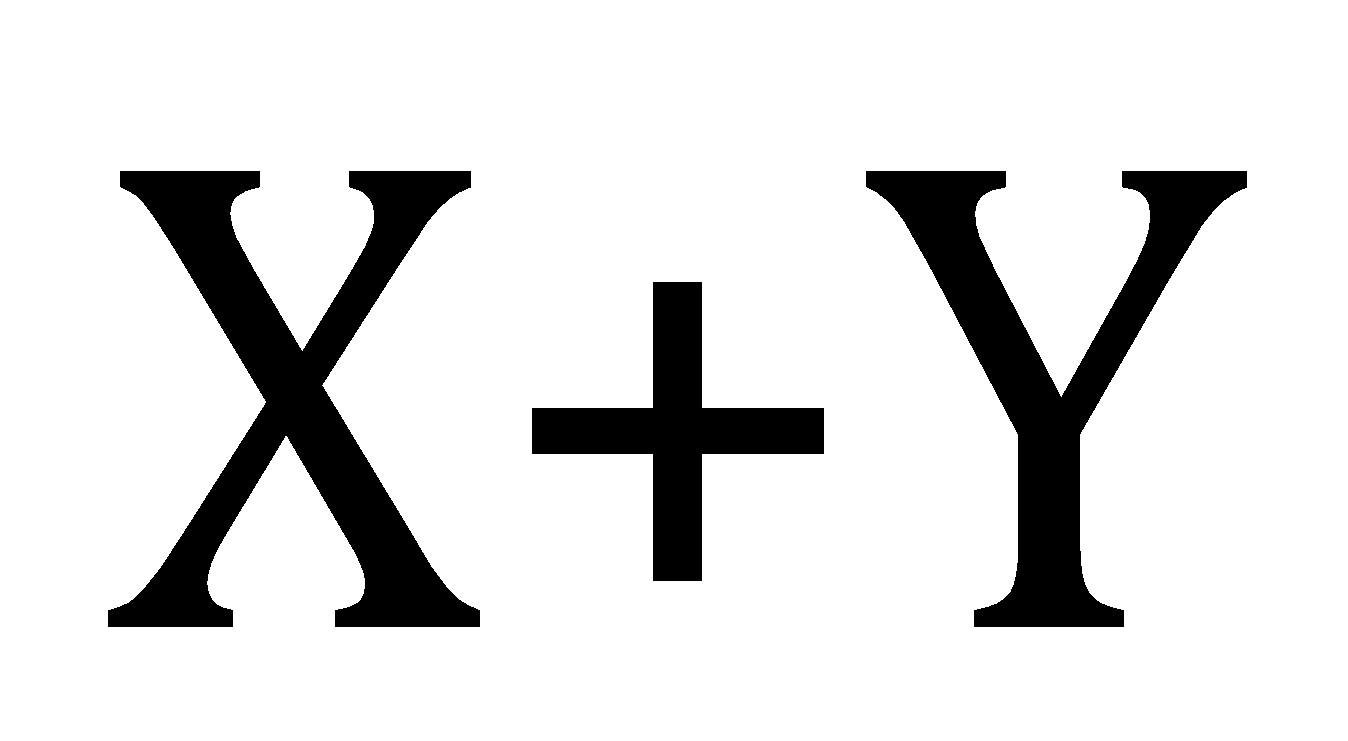
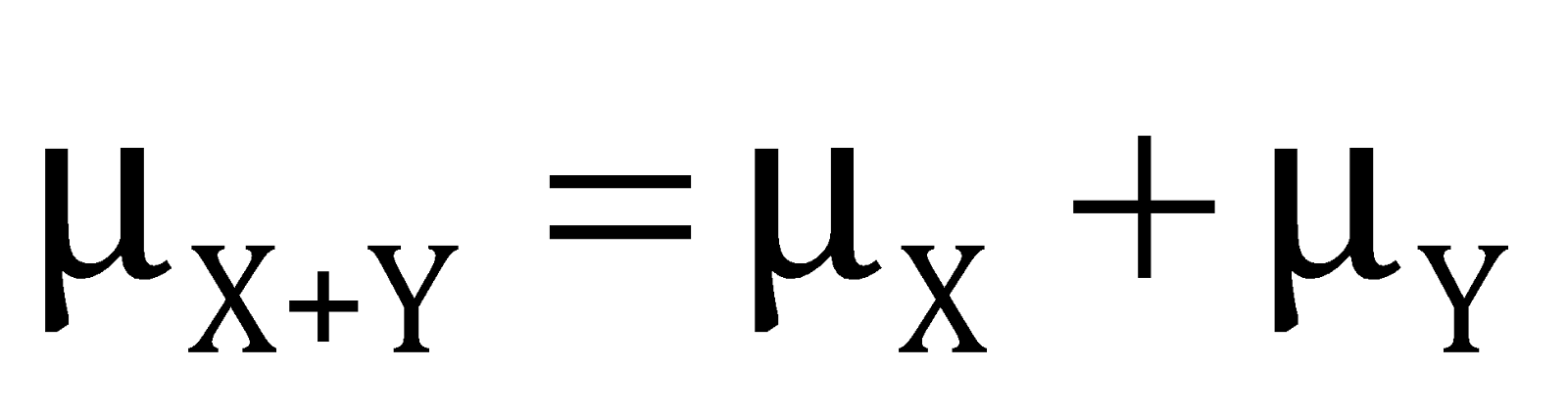
and standard deviation can be obtained by the relation,
.
Moreover, for the new random variable 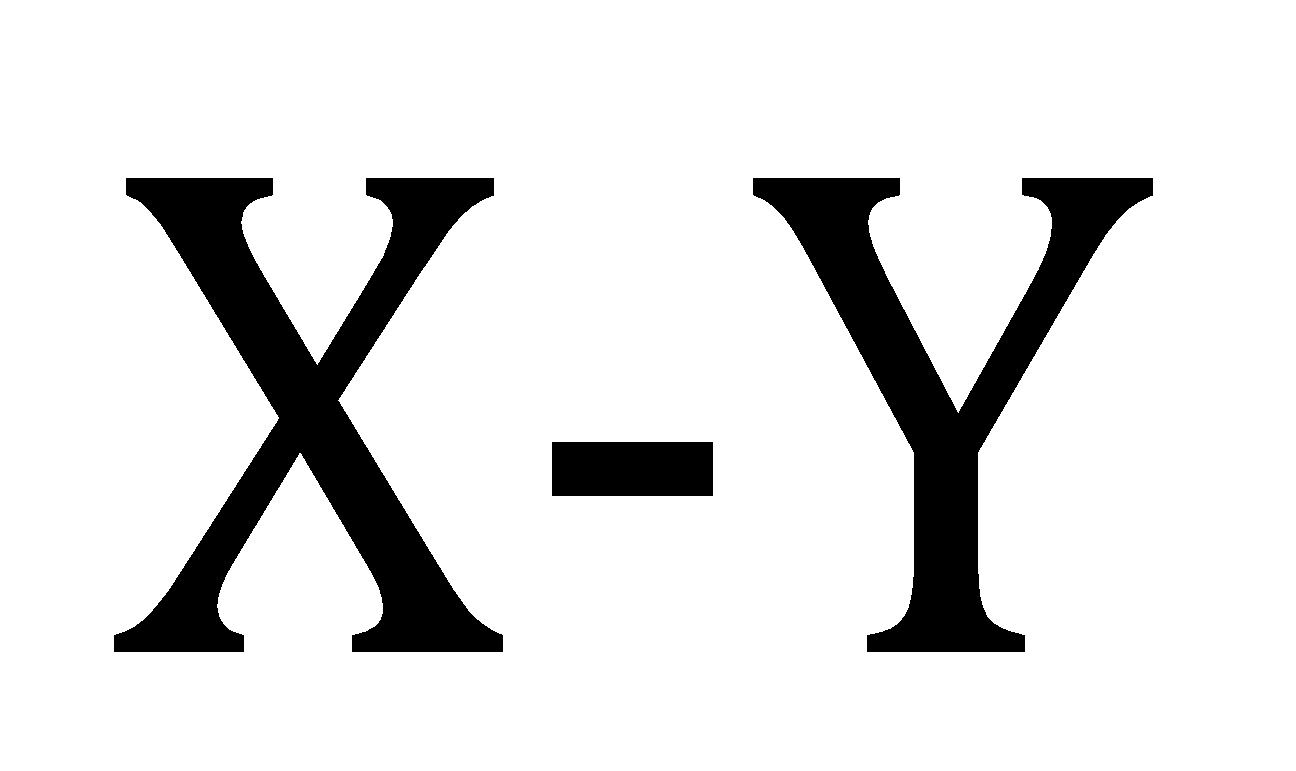
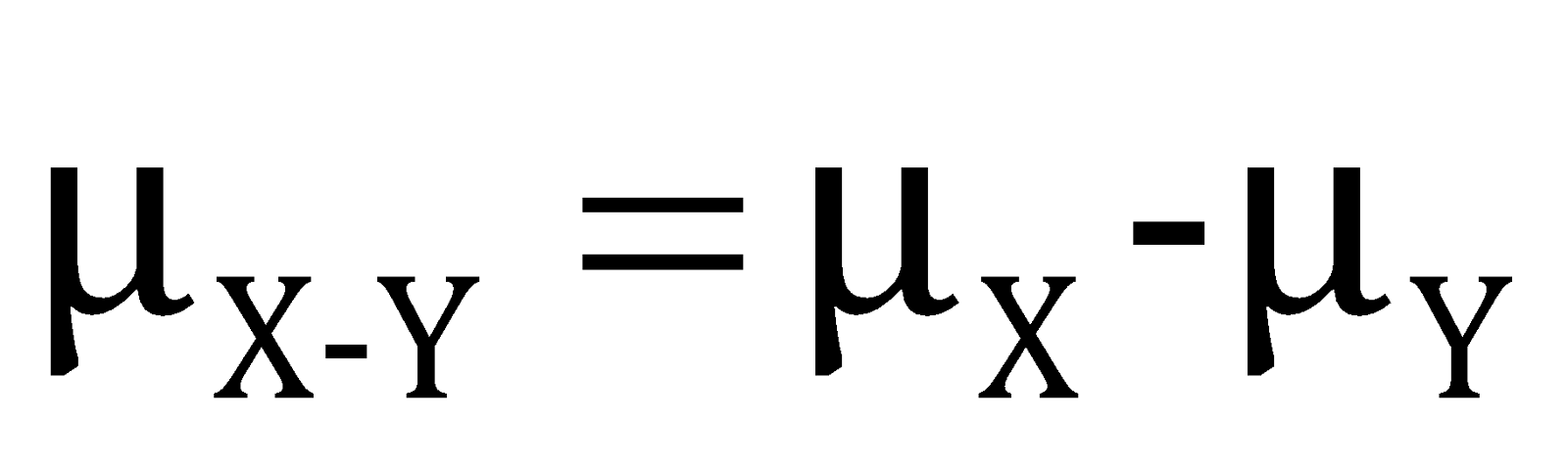
and standard deviation can be obtained by the relation,
.
Conclusion
Thus the random variables are the outcome of a random experiment, where the previous and future experiments are not related to one another. The random variables can be categorised as the discrete or continuous random variables, which select the finite or infinite number of values, respectively. These random variables can be utilised to obtain the new set of the random variables after the certain mathematical operations such as addition, multiplication, etc.
Solved Examples
Q1. What is the expected or mean value of the random experiment of rolling a dice?
Solution: The random variable
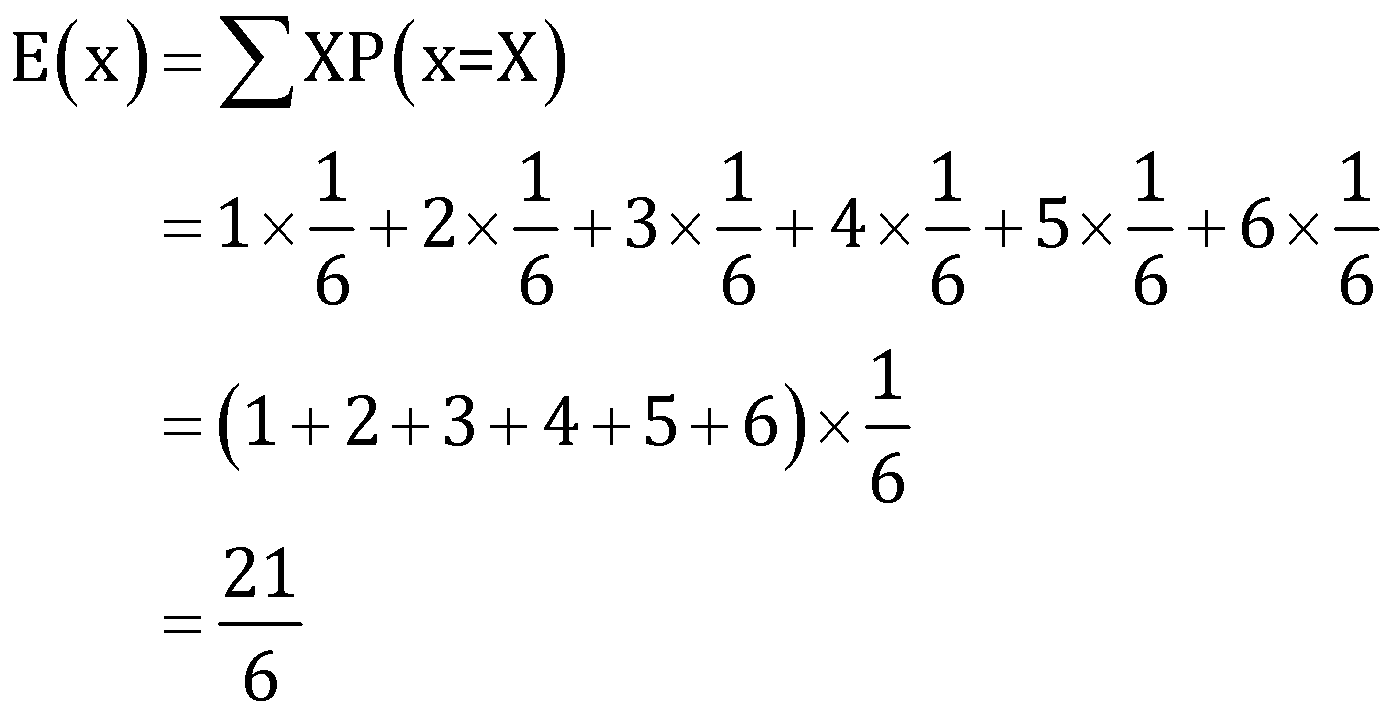
Therefore, the expected value of the random experiment of rolling a dice is .
Q2. What is the standard deviation of the random experiment of rolling a dice?
Solution: The random variable
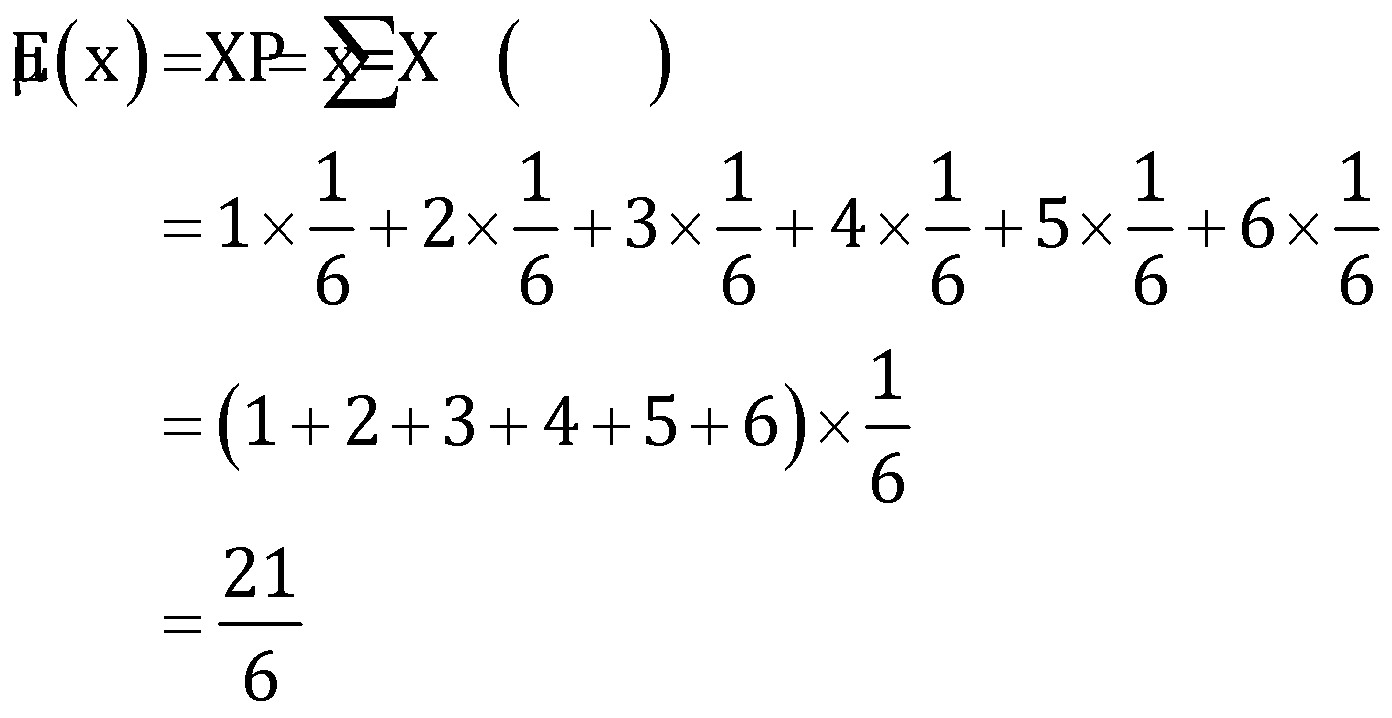
Therefore, the expected value of the random experiment of rolling a dice is .
The standard deviation of the experiment can be defined as,
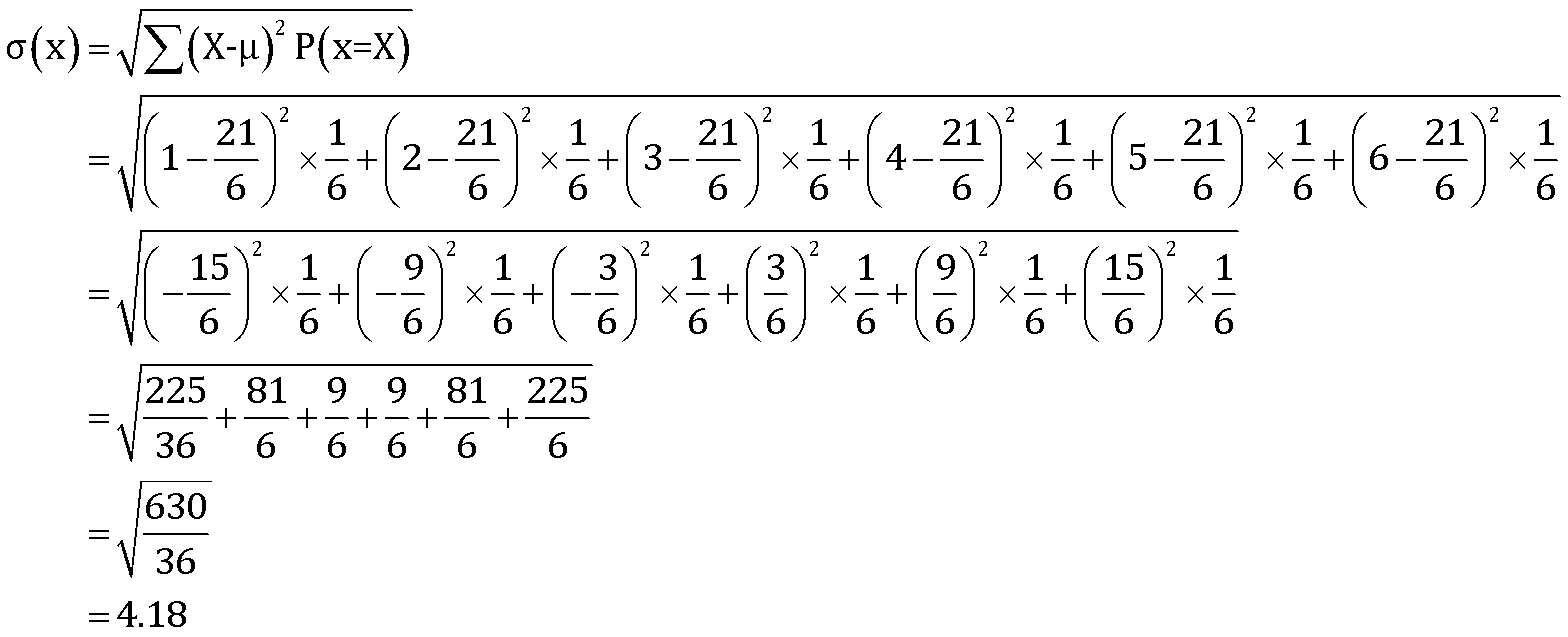
Therefore, the standard deviation of the random experiment of rolling a dice is .
Q3. The average height of a class is 157 cm. Suppose that everyone needs to wear stilts for a school play. The stilts increase the height of the wearer by 5 cm. What is the average height of the class when everyone is wearing stilts?
Solution: Here the random variable is the height of the students of the class, if we consider it 
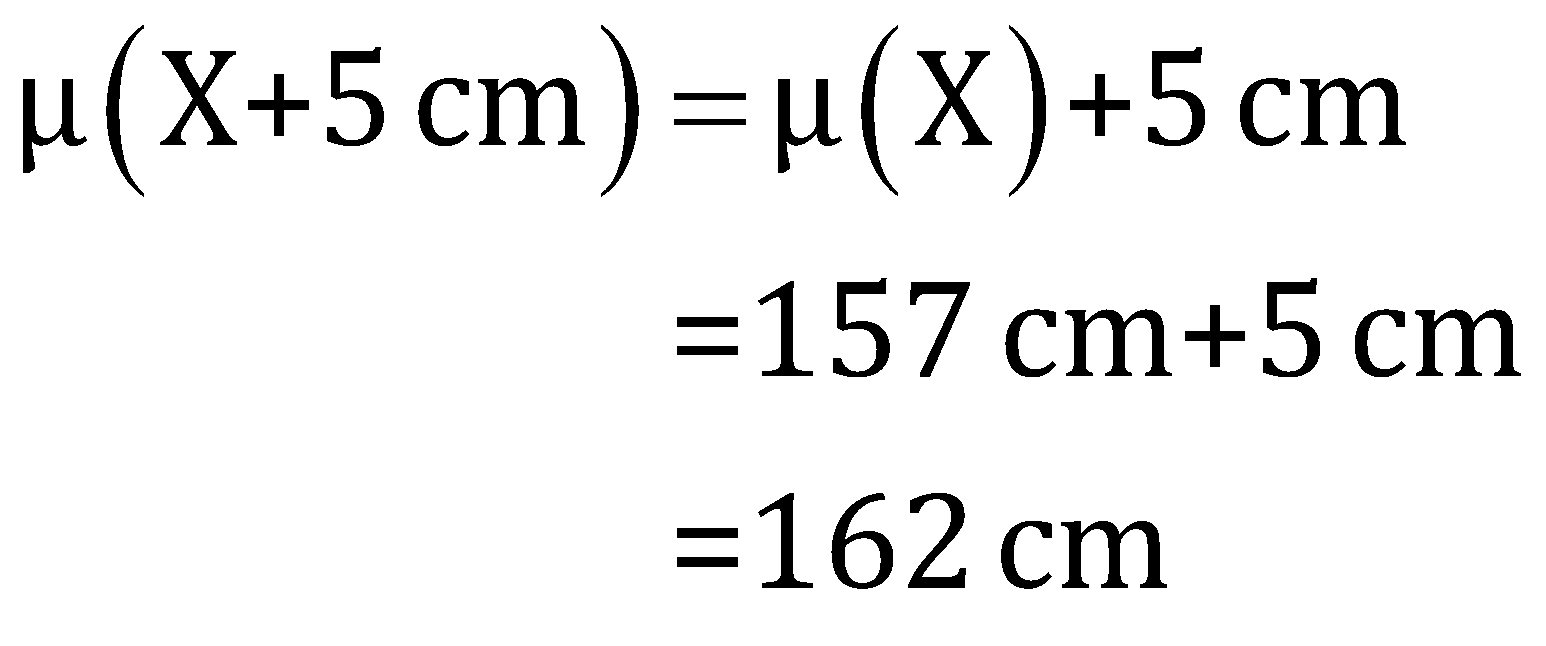
Thus, the new average of the height of the class is 162 cm.
Q4. The average salary of the employees of a company is 5000 bucks. Suppose that the salary of each employee is increased three times after the company records a growth. What is the average salary of the employees After increment?
Solution: Here the random variable is the salary of the employees of the company if we consider it
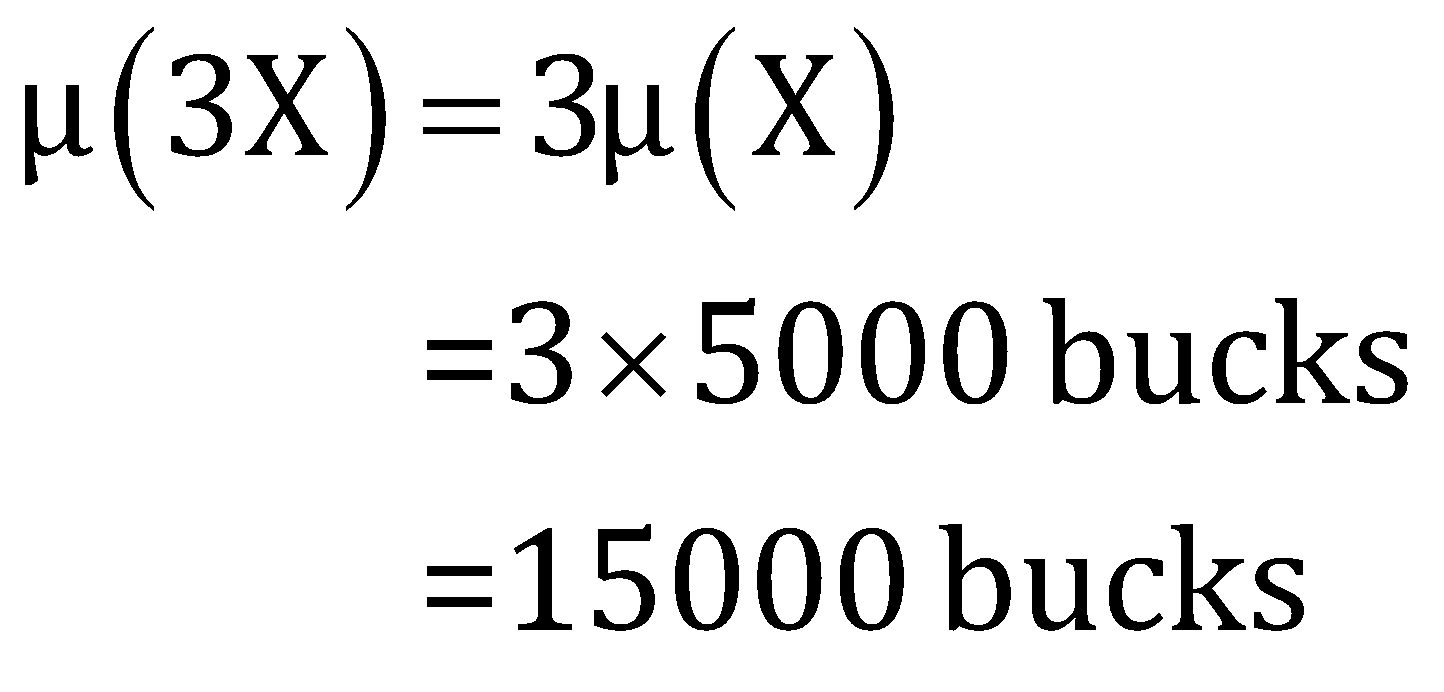
Thus, the new average salary of the employees is 15000 bucks.
Q5. If for two given random variables , the mean values are 5 and 8, respectively, while the standard deviation is given by the 20 and 10, respectively. Then what will the mean and standard deviation of the combined data set obtained after sum of these random variables?
Solution: The new dataset obtained from the sim of the random variables is 
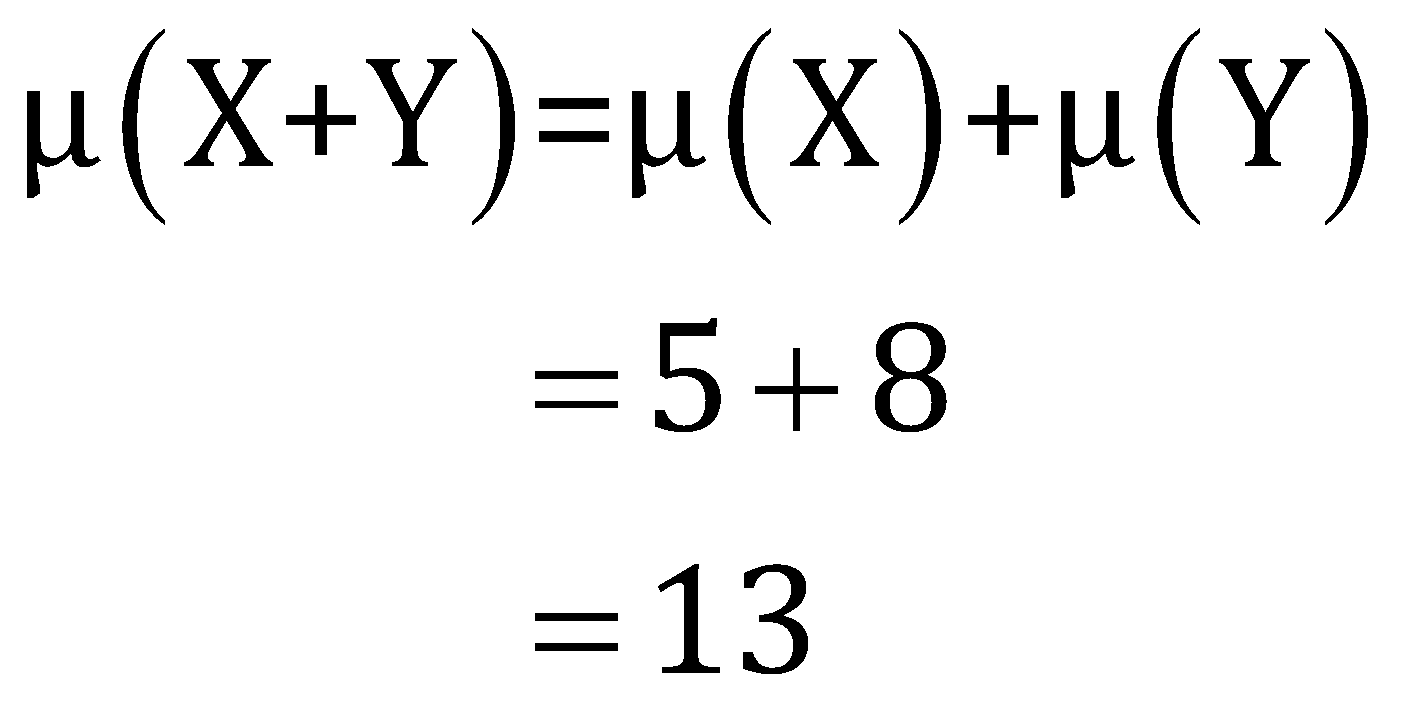
Now, the standard of the combined data set can be obtained from the relation,
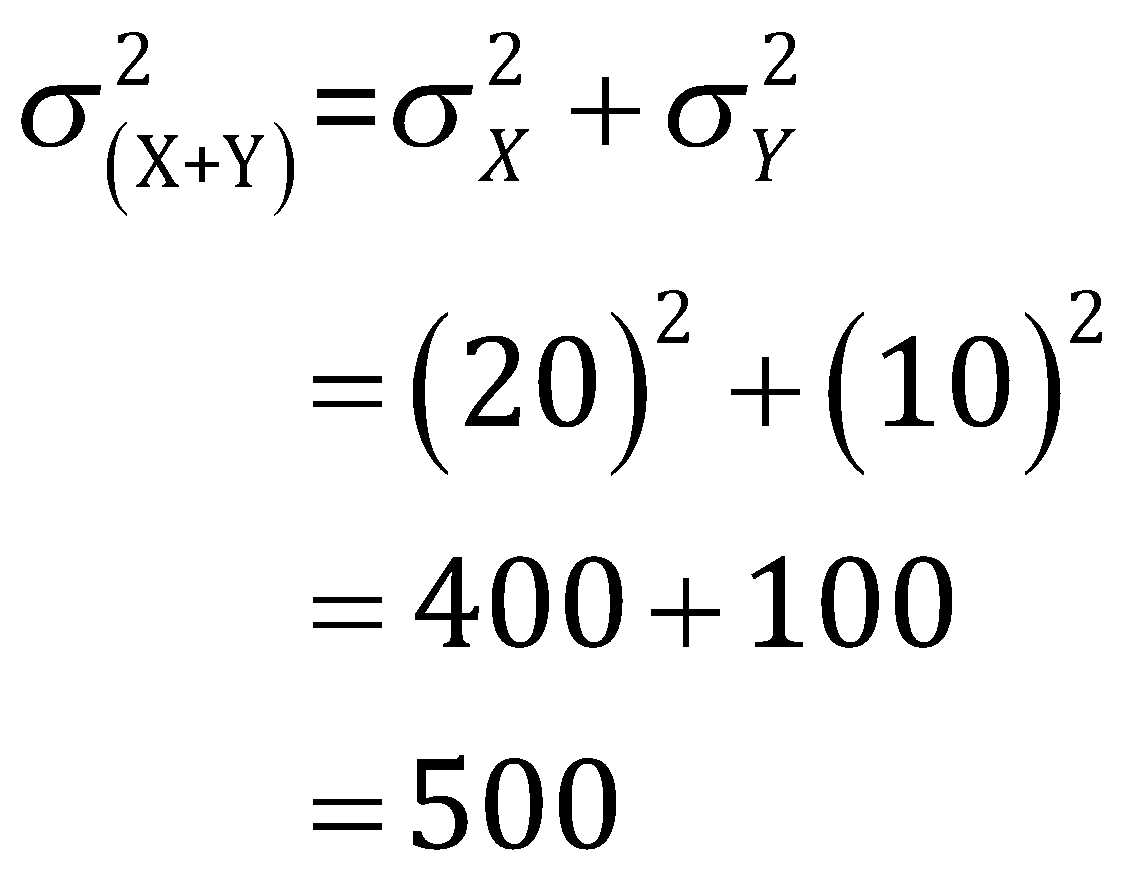
Thus,
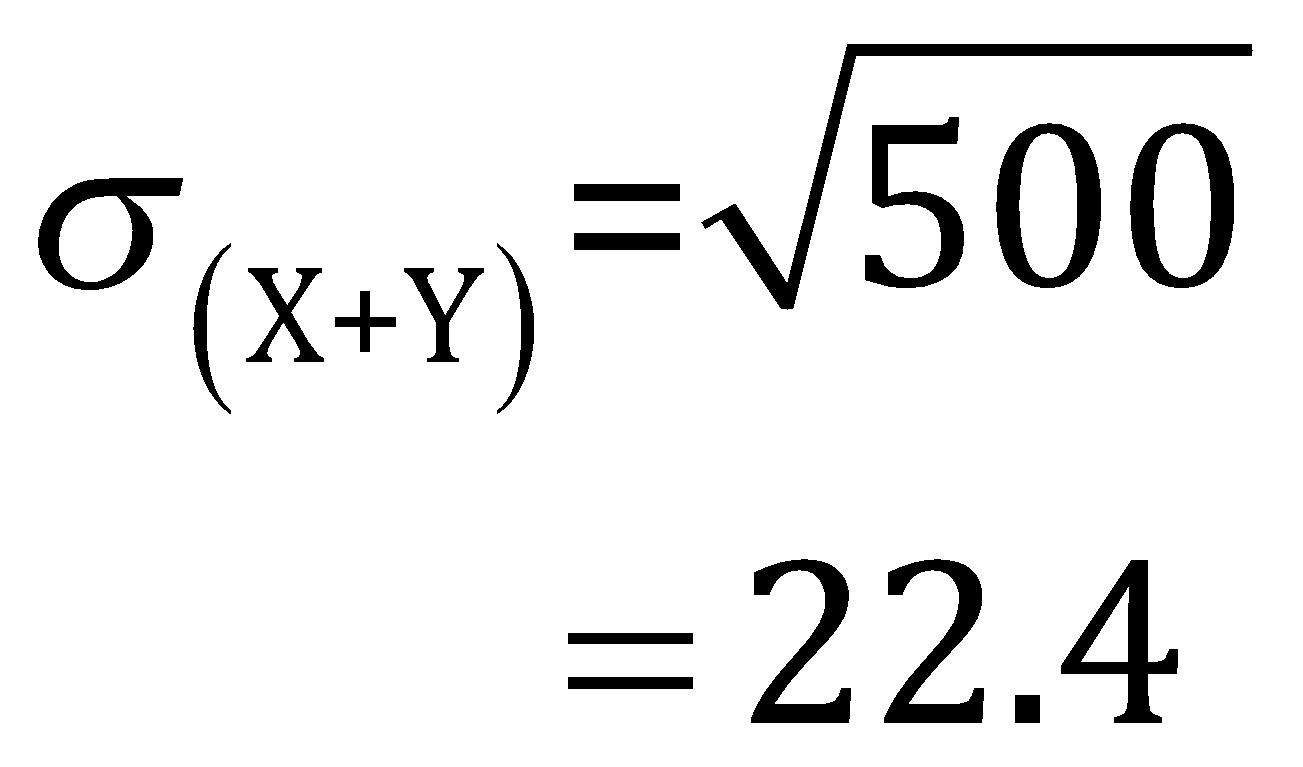
Therefore, the mean and standard deviation of the combined data set are 13 and 22.4, respectively.
Frequently Asked Questions
Q1. What is the requirement of combining the two or more random variables?
Since the combination of the two or more random variables give origin to a new series of the random variables without doing the random experiment again, therefore the combination of the random variables finds wide application in the statistics.
Q2. Why do we transform random variables?
The random variables are transformed by the application of mathematical functions, and this facilitates us to study the given data sets in more depth by using those mathematical factors into it. For example, for a given set of the height of the students of a class we can study their relationship with the other class, year, etc.
Q3. How can one differentiate between the discrete and continuous random variables?
The discrete random variables are obtained by counting the data set since its values are finite and defined; however the continuous random variables can take any value of the given interval. A number obtained after the rolling of a dice is an example of the discrete random variable, while distance travelled by a vehicle at any instant of time is an example of the continuous random variable.
Q4. What is the difference between a variable and a random variable?
A variable is defined for the definite values which it can take in the algebra, however a random variable can take any values from a defined set randomly.
Q5. What are the characteristics of the random variables?
The different characteristics of the random variable are as follows:
- They can only have real values.
- The random variables choose their values randomly or stochastically.
- The random variable can be transformed into the new set of random variables after certain mathematical transformations.
References
- Combining random variables (CS 2800, Spring 2017). (n.d.). Cornell Computer Science. Retrieved January 27, 2023, from http://www.cs.cornell.edu/courses/cs2800/2017sp/lectures/lec15-combining.html
- Random Variable | Definition, Types, Formula & Example. (n.d.). Byjus. Retrieved January 27, 2023, from https://byjus.com/maths/random-variable/
Random Variable: What is it in Statistics? (n.d.). Statistics How To. Retrieved January 27, 2023, from https://www.statisticshowto.com/random-variable/
Mar 11, 2025
Was this helpful?



