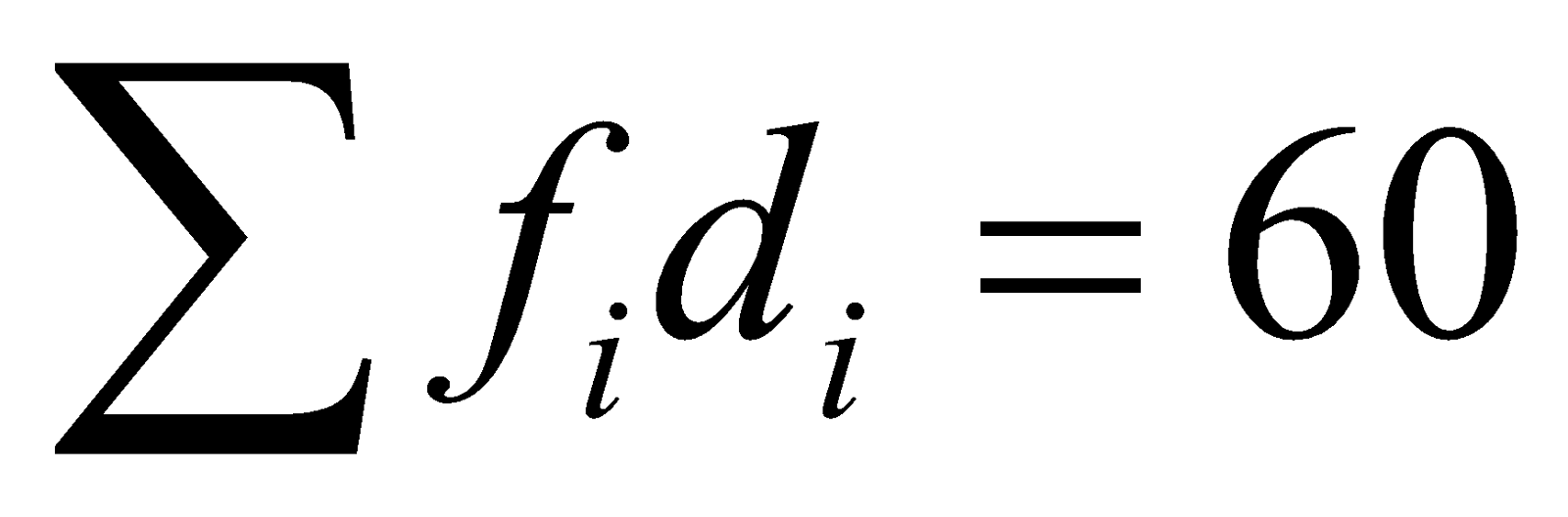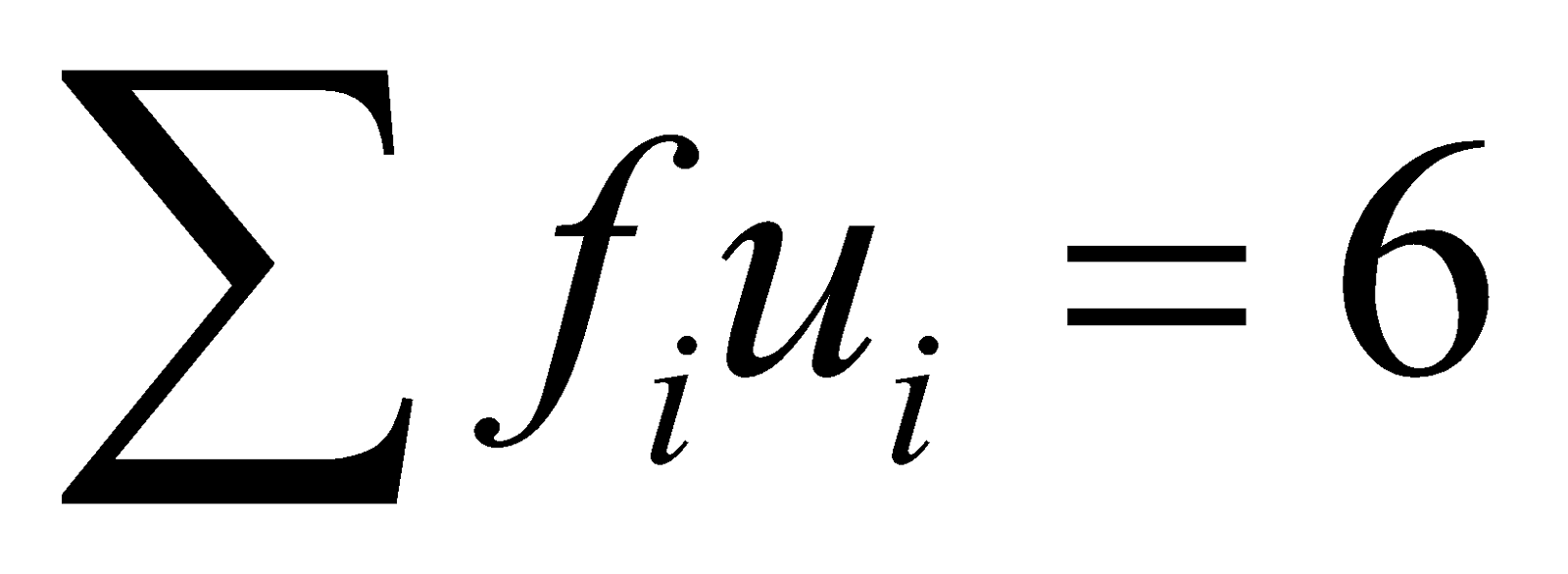What are the Differences Between Mean and Median?
By Shifa Ali on Jul 04, 2024
Updated Mar 10, 2025

In this article
Introduction
Central tendencies are a measure of centralizing values in a data set, i.e., they measure some sort of average value of the observations in a survey or an experiment. There are three most basic measures of central tendencies, Mean, Median and Mode. In this article, we are going to learn about Mean and Median, how to find them, their properties and applications.
Looking for last minute help for your AP Statistics exam in May? Find an expert 1-on-1 online AP Statistics tutor from Wiingy and give your exam prep a boost!
Data and Central Tendencies
A data is a collection of observation values in a survey or an experiment. In a data usually the frequency of the observations tends to have higher density towards the center, i.e., the frequency-observation graph peaks near the center. Thus, we can assume the values near the center tend to give a lot of information about the data, and thus we define central tendencies. Central Tendencies are quantities about a data set that tell a certain central value of the data. Central Tendencies may or may not actually belong to the data set.
Mean and Median
Mean is defined as the average value of the observations in a data set, i.e., it represents the center of the data set values by the average of all the data points. There are 3 different types of mean in mathematics, Arithmetic mean, Geometric mean and Harmonic mean, each corresponding to a different relation between the data points. 2 data points and their arithmetic mean form an arithmetic sequence, i.e., the difference between two consecutive terms have constant difference, similarly geometric mean forms a geometric sequence and harmonic mean forms a harmonic sequence. For the sake of simplicity and practicality we mainly focus on arithmetic mean in statistics.
The arithmetic mean is defined as the average value. It is calculated by dividing the sum of all the observations by the total number of observations.
Median is the middle term of all the observations arranged in ascending or descending order.
How to Find Mean and Median
Mean
- Ungrouped data
To find mean of a discrete data, i.e., an ungrouped data, we simply add all the observations and divide that sum by the number of observations, thus the formula for the mean of an ungrouped data is given by,
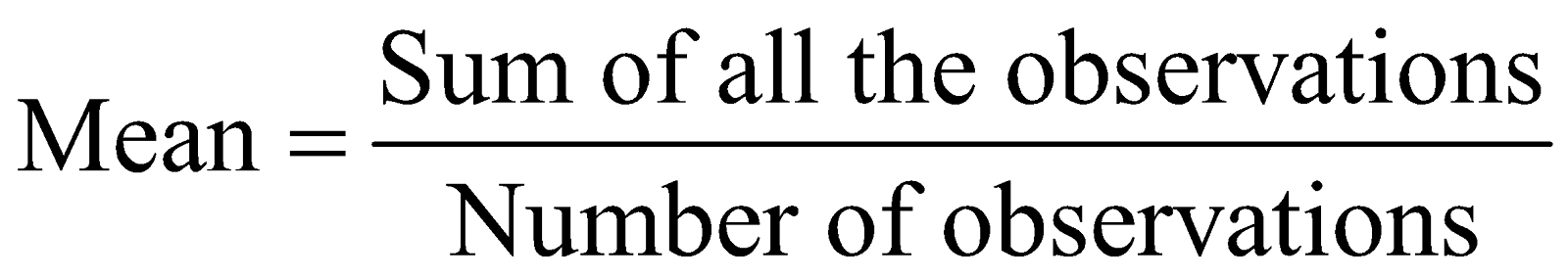
- Grouped Data
To find the mean of a grouped data, we have two different types of grouping of data.
- Simple Grouping: In simple grouping of data, we simply group the data with same value. This type of grouping is practical only for a small sample set. To find the mean in simple grouping we first find the total value each data point is contributing towards the data by multiplying the data values by their respective frequency, and then we add all these values found by the product of data point and their frequency. Then that sum is divided by the total number of observations which is simply the sum of all the frequencies.
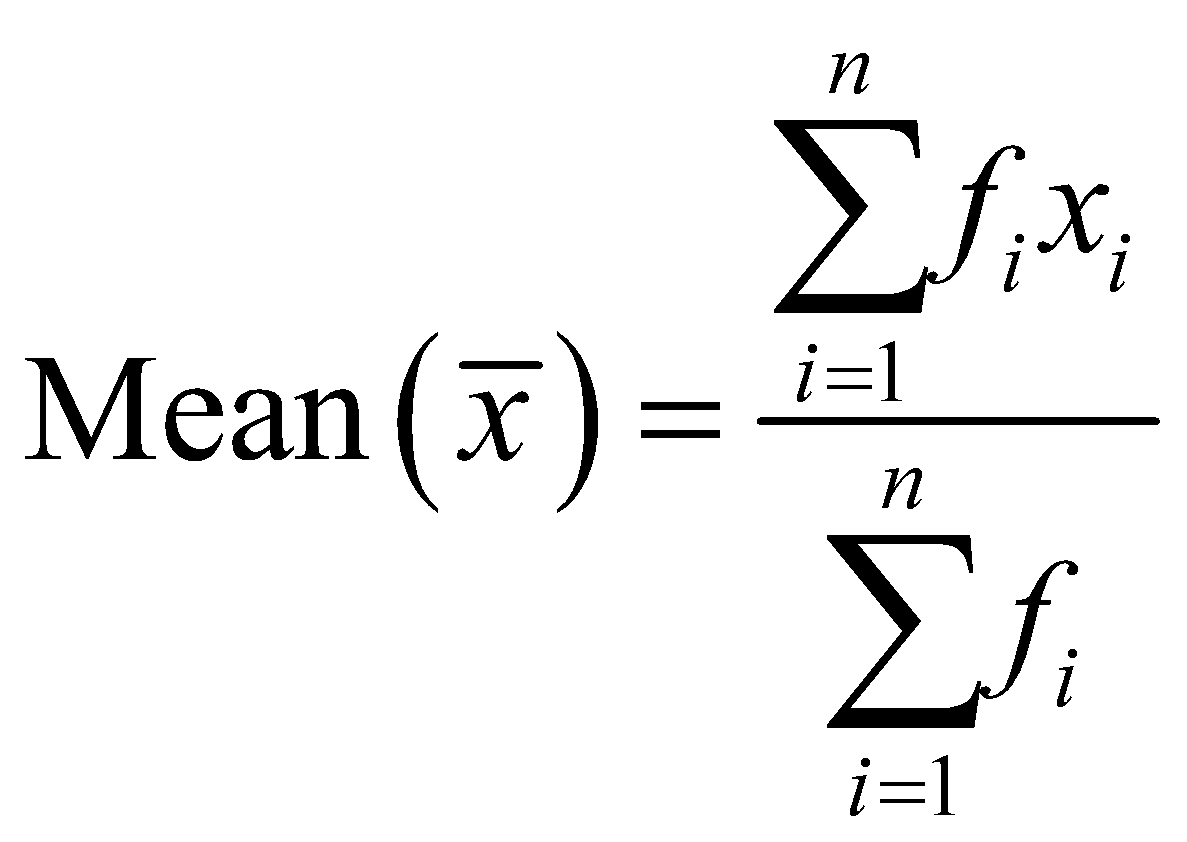
Where, ’s are the observations, and ’s are their respective frequencies.
- Ranged Grouping: In ranged grouping of data, we divide the total range of the data, i.e., the highest value to lowest value into small class intervals, and any value falling into a range of class interval is counted towards that class interval only. This type of grouping is practical only for a large sample set, for small sample sets it may vary from the mean found by simple grouping or ungrouped data, since it approximates the value of all the data points in a given interval to a single point. But in large data set that approximation becomes relatively irrelevant and the mean found is a very good approximate of the actual mean. In ranged grouping, according to the value of each data set we can apply three different methods to find the mean, i.e., Direct method, Assumed mean method and Step-Deviation method. Let’s learn more about each of these methods more in later sections with examples. The formula for mean using direct method is,
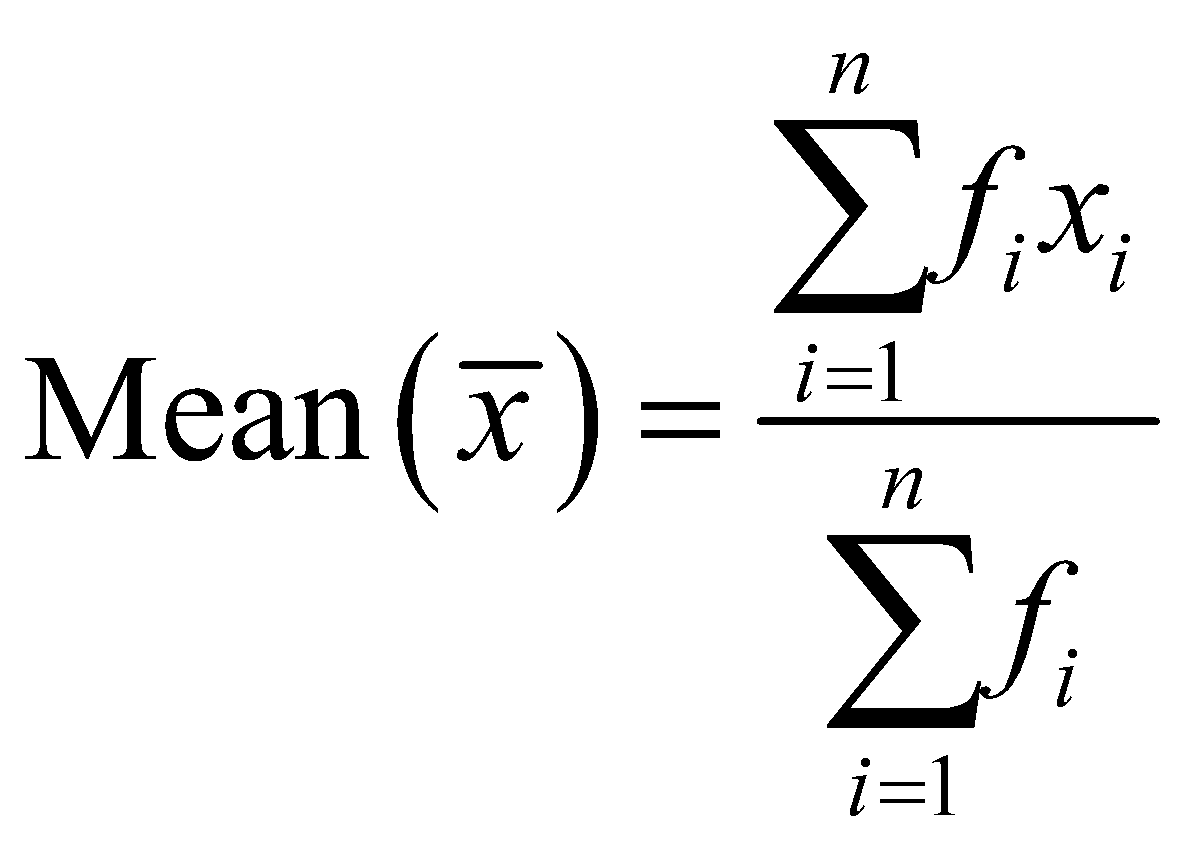
Where, ’s are the class marks, and ’s are their respective frequencies.
The formula for Assumed mean method is
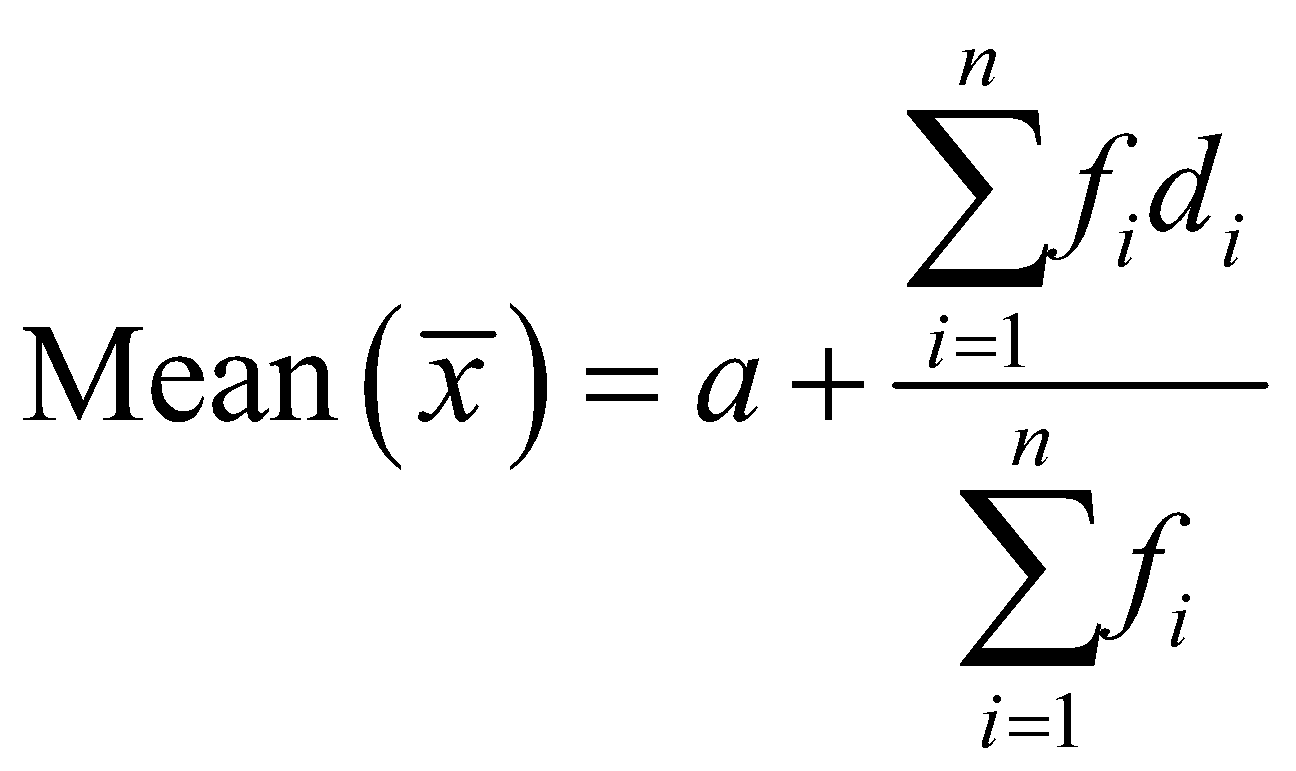
Where, ’s are the differences between class marks and assumed mean , and ’s are their respective frequencies.
The formula for Step Deviation method is,
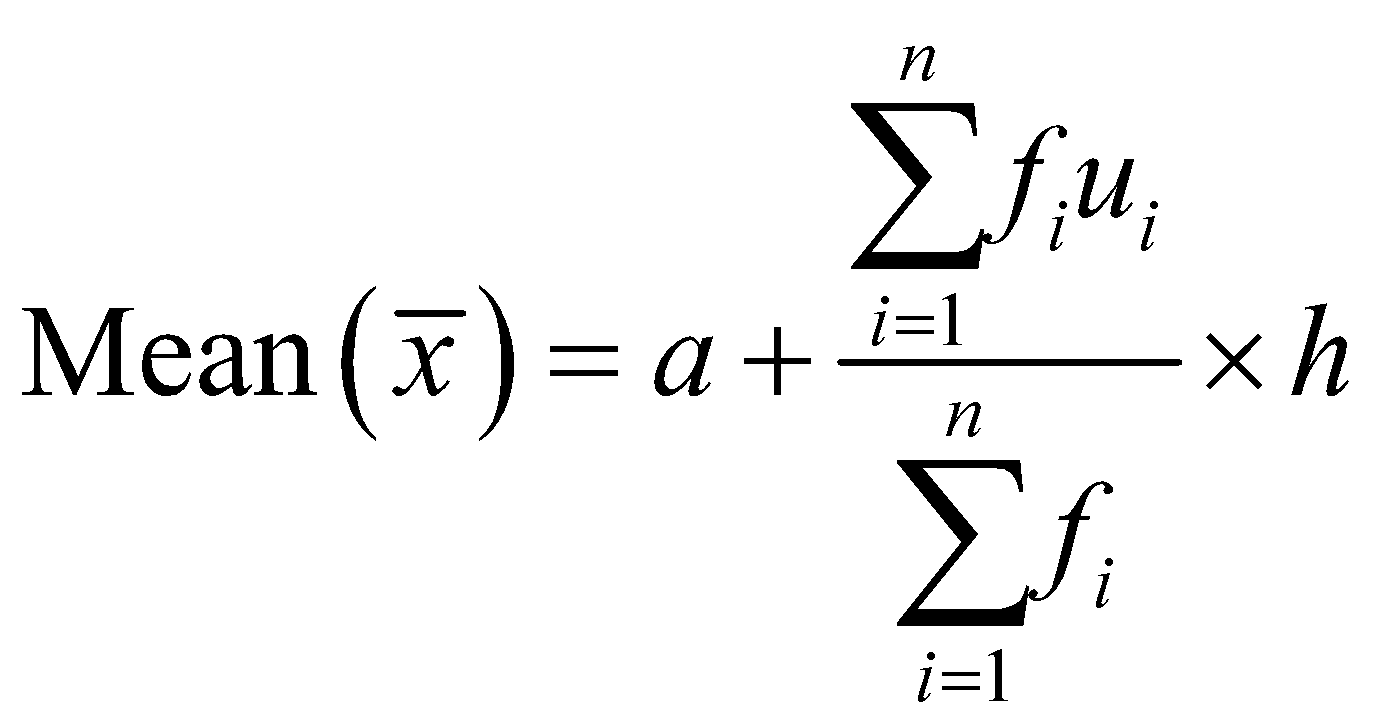
Where, ’s are the ratios of differences between class marks and assumed mean with respect to the class height , and ’s are their respective frequencies.
Median
- Ungrouped Data
To find the median of an ungrouped data we arrange the data in a monotone, i.e., either ascending or descending order, then we select the middle most value from the arranged data. If the number of observations is odd then we simply pick out the middle most data point. But if the number of observations is even then we have two middle most data points, then we find the arithmetic mean of those two points.
- Grouped Data
To find the median of a grouped data we have two methods, i.e., numerical and geometrical. Both methods have the same basis known as cumulative frequency method. We can make the cumulative frequency table in two ways, i.e., ‘More than’ table and ‘Less than’ table, median found numerically from both the tables is same and we have a simple formula for finding the median. Graphically More than cumulative frequency table results in a More than Ogive and the Less than table in Less than Ogive, the value of the data at the intersection of both ogives gives the median.
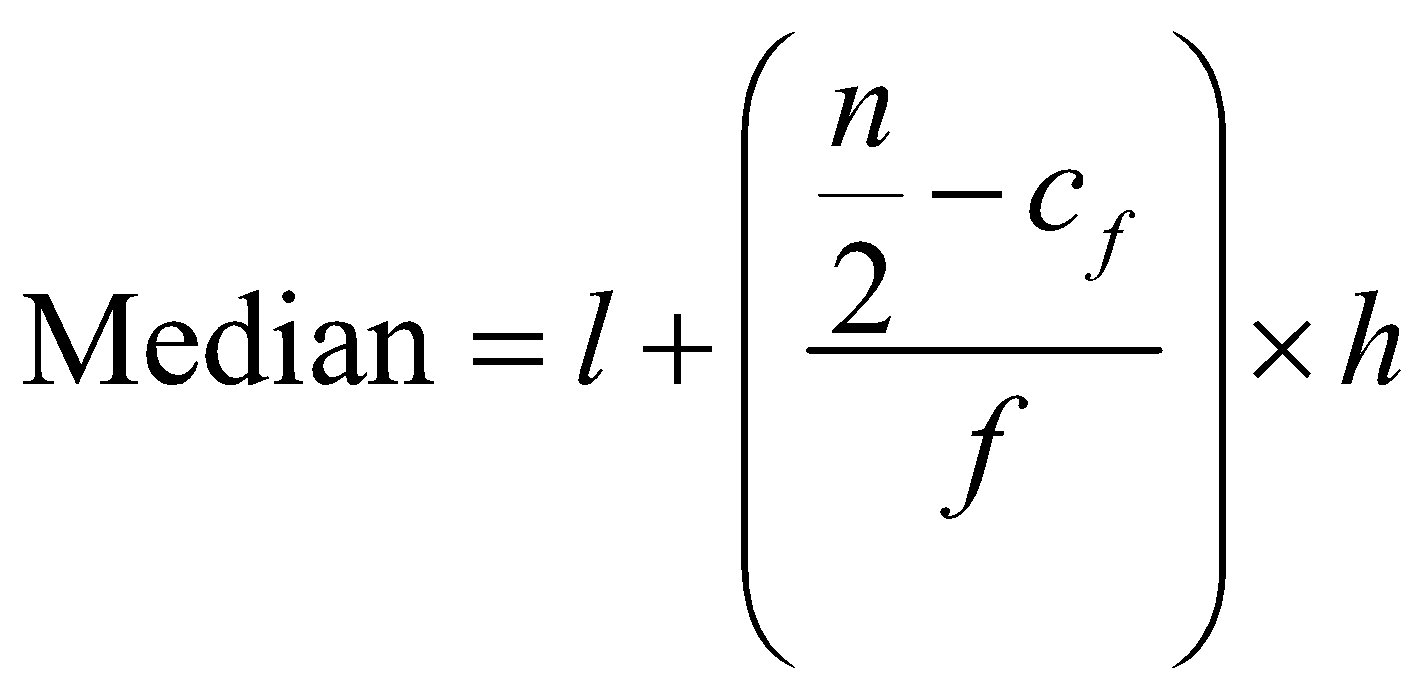
Where, is the lower limit, is the frequency of the median class and is cumulative frequency of the class preceding the median class and is the total number of observations or simply the total frequency and is the height of the class intervals. Median class is selected by choosing the class that has cumulative frequency just more than the value .
Differences between Mean and Median
| Mean | Median |
| Mean is the average value of all the data points, the mean of a data set may or may not actually belong to the data set. | Median is the middle point of a data set. The median of a data set always belongs to the data set. |
| Mean of a data set depends on all the data points. | Median of a data set does not actually depend on all the data points, just the center points. If all the right half is increased and all of the left half is decreased, the median remains the same. |
| Mean of a data set is most sensitive central tendency out of the three. Mean of the data set changes if any value of the data set is changed. | Median of a data set is not too sensitive to the change in data points. Median of a data set does not necessarily change when any one of the data points is changed. |
| Mean is the preferred central tendency when the data is distributed normally. | Median is the preferred central tendency when the data is formed by skewed distribution. |
Conclusion
In this article, we have learned about Mean and Median as central tendencies. Mean is the average value of all the observations of all the data points, whereas median is the middle most data point. When the data is formed by normal distribution, we prefer to use the mean as the central tendency as in a normal distribution the variance is optimum, where as if the data is formed by skewed distribution, we prefer the median as the central tendency since the data is weighted to one of the sides, and hence, the mean is not near the actual center.
Solved Examples
Example 1: Find the mean and median for the following data set.
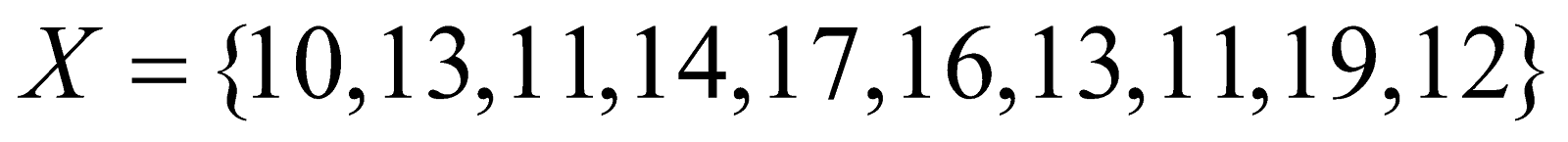
Solution:
The mean of the given data set is given by
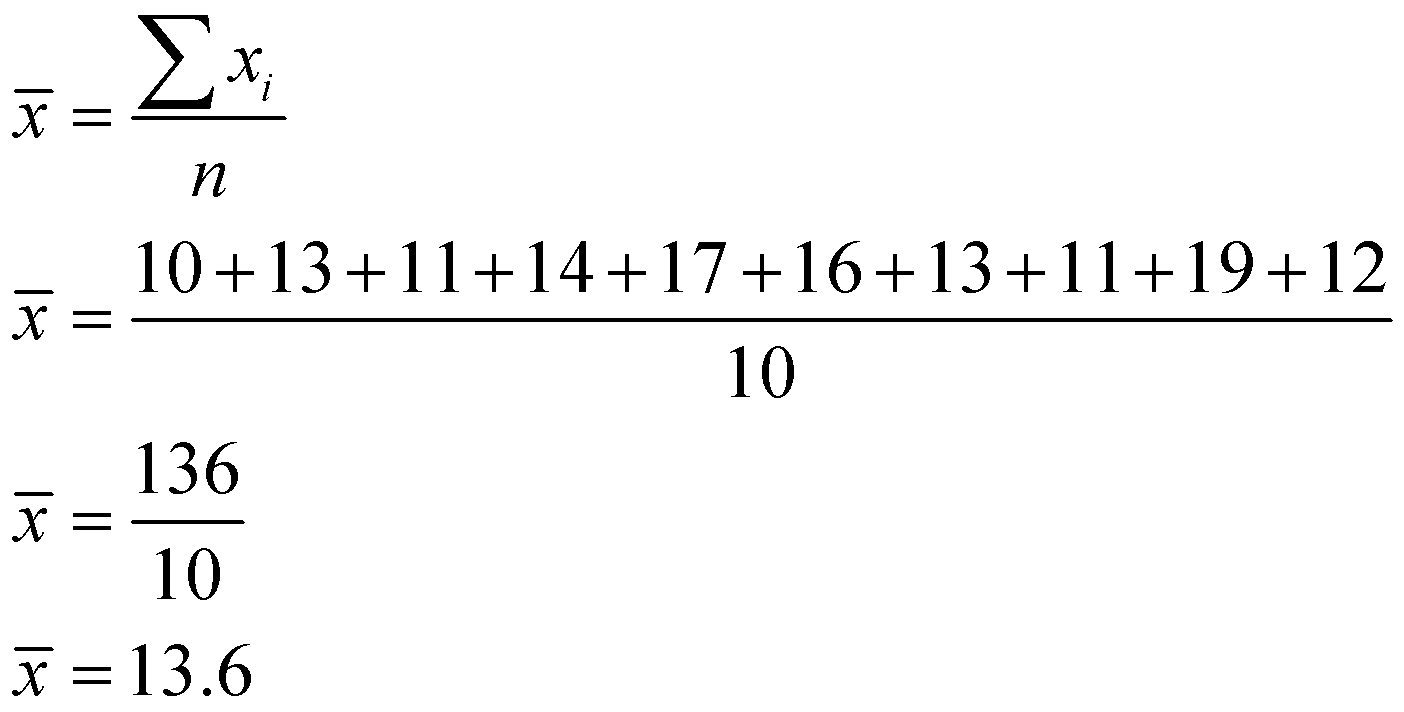
And since the number of observations is even, the median is the arithmetic mean of the middle most term in the arranged data set 
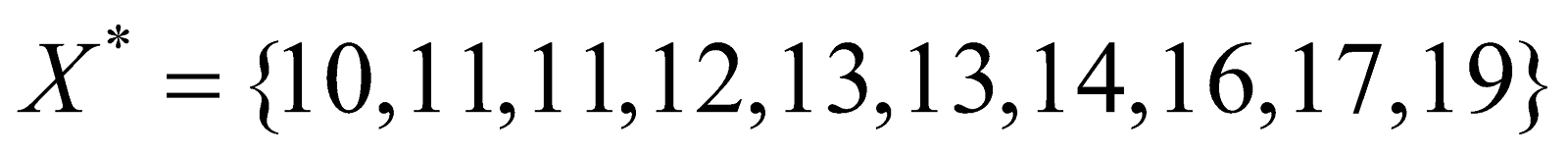
Thus, median is given by
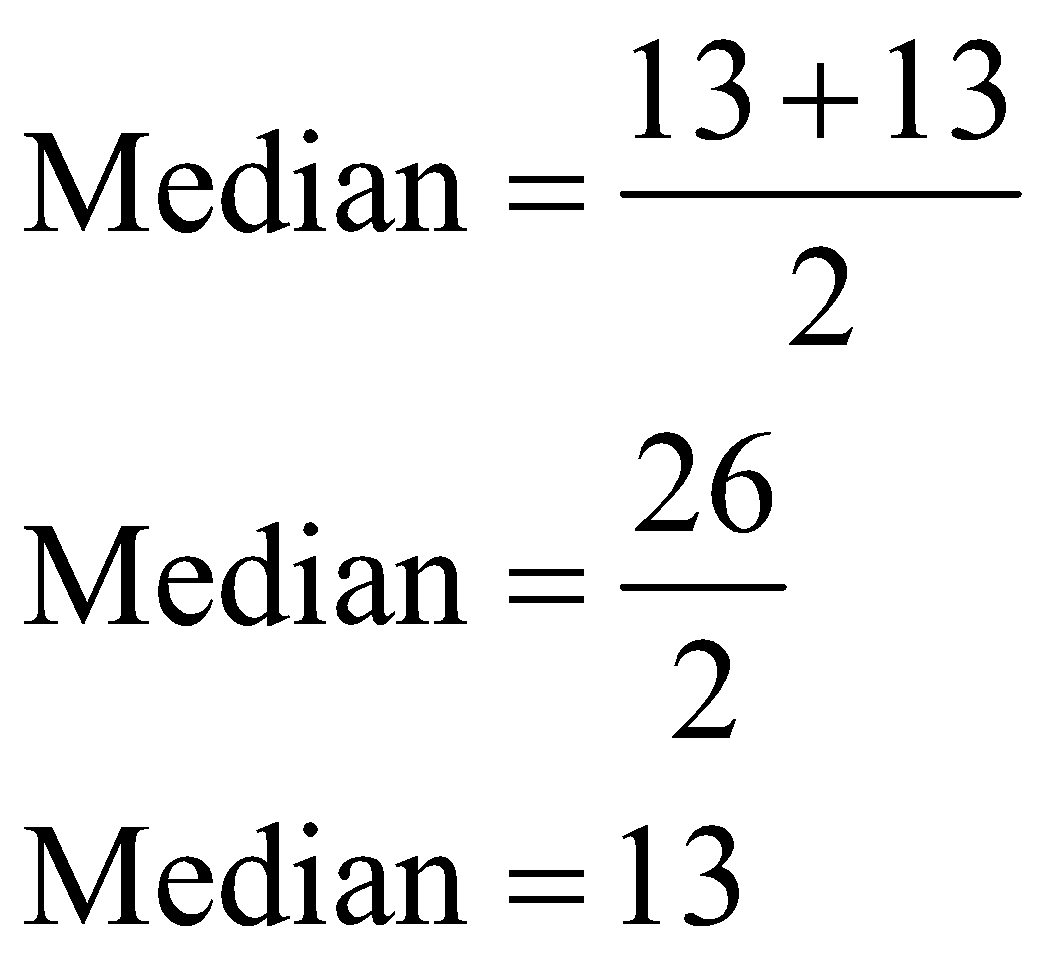
Example 2: Find the mean of the following grouped data by all three methods and verify your answers. Also find the median using More than cumulative frequency distribution.
| Class Intervals | 0-10 | 10-20 | 20-30 | 30-40 | 40-50 |
| Frequency | 6 | 10 | 14 | 12 | 8 |
Solution:
To find the mean we will construct the following distribution table
| Class Intervals | Class Marks | Frequency | 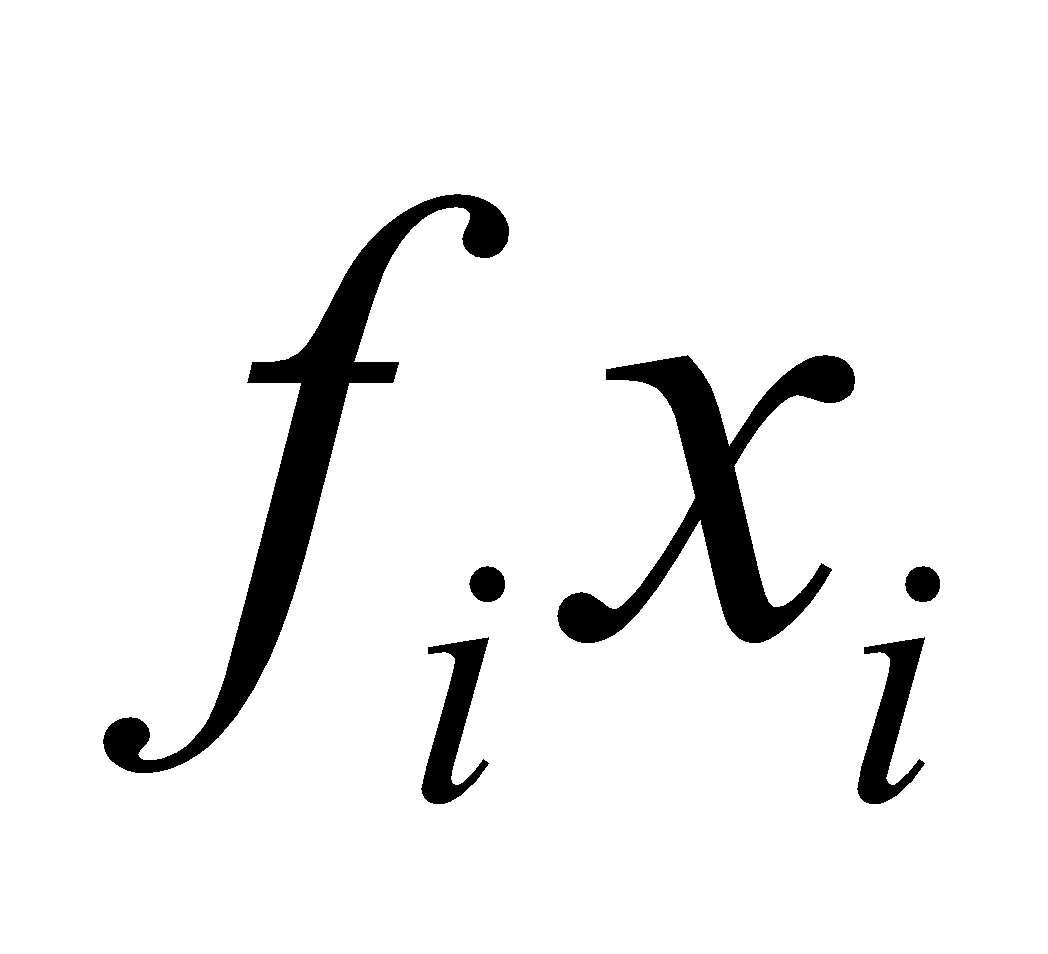 | 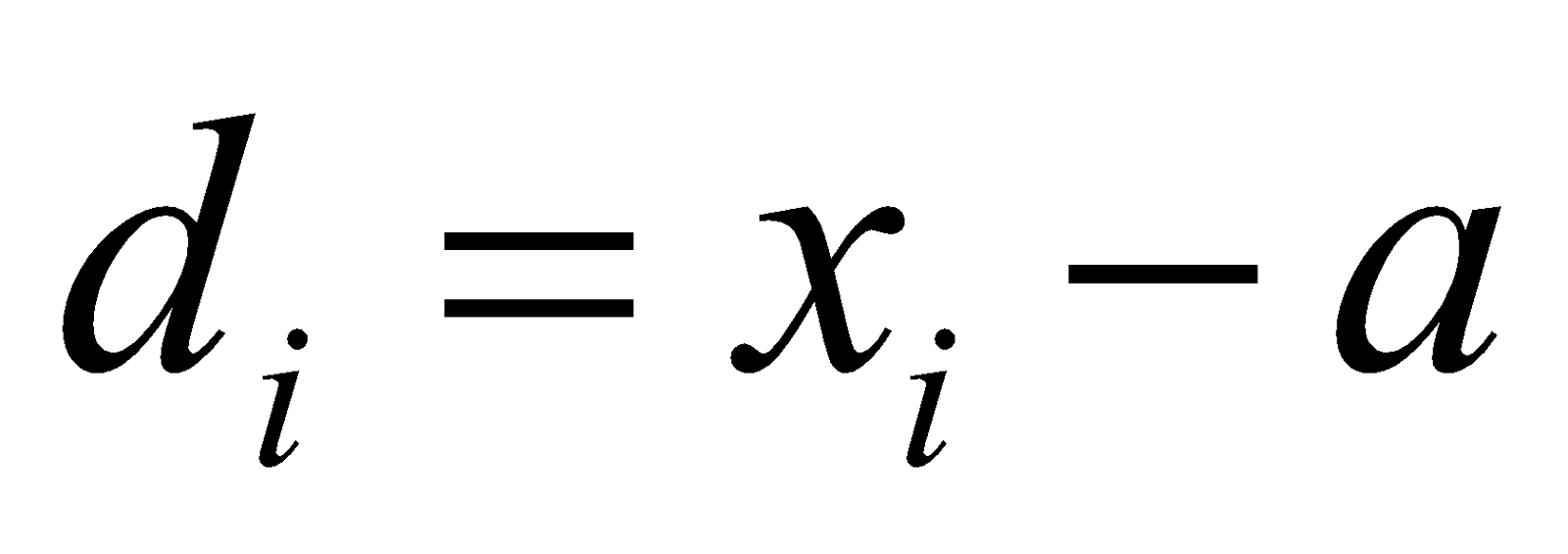 | 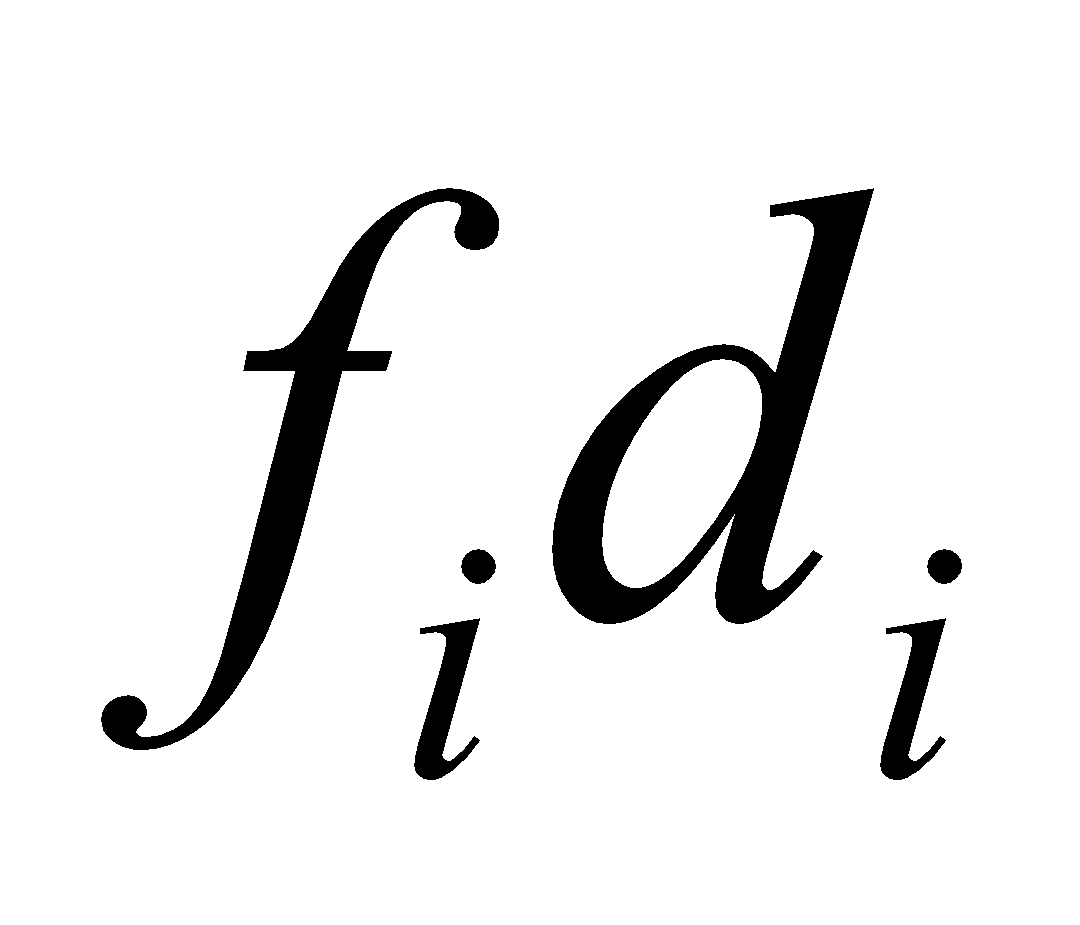 |  | 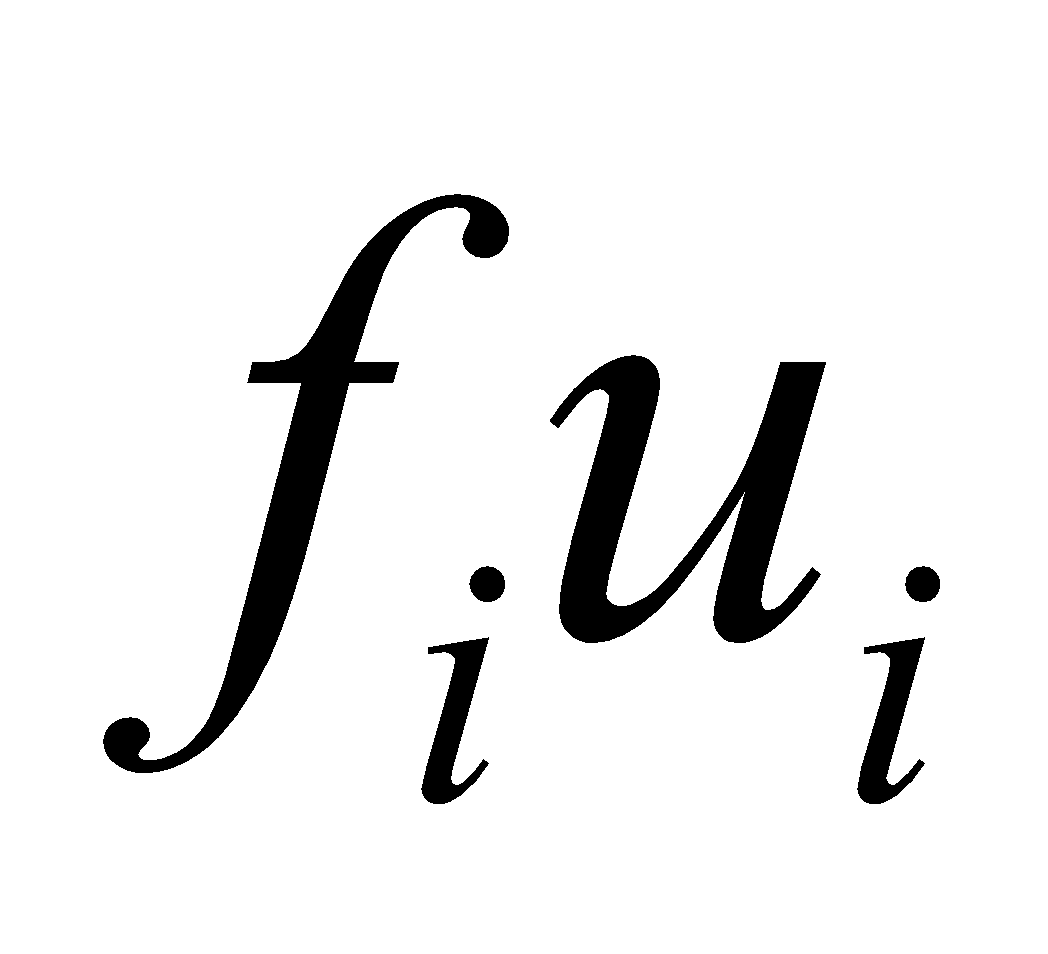 |
| 0-10 | 5 | 6 | 30 | -20 | -120 | -2 | -12 |
| 10-20 | 15 | 10 | 150 | -10 | -100 | -1 | -10 |
| 20-30 | 25 | 14 | 350 | 0 | 0 | 0 | 0 |
| 30-40 | 35 | 12 | 420 | 10 | 120 | 1 | 12 |
| 40-50 | 45 | 8 | 360 | 20 | 160 | 2 | 16 |
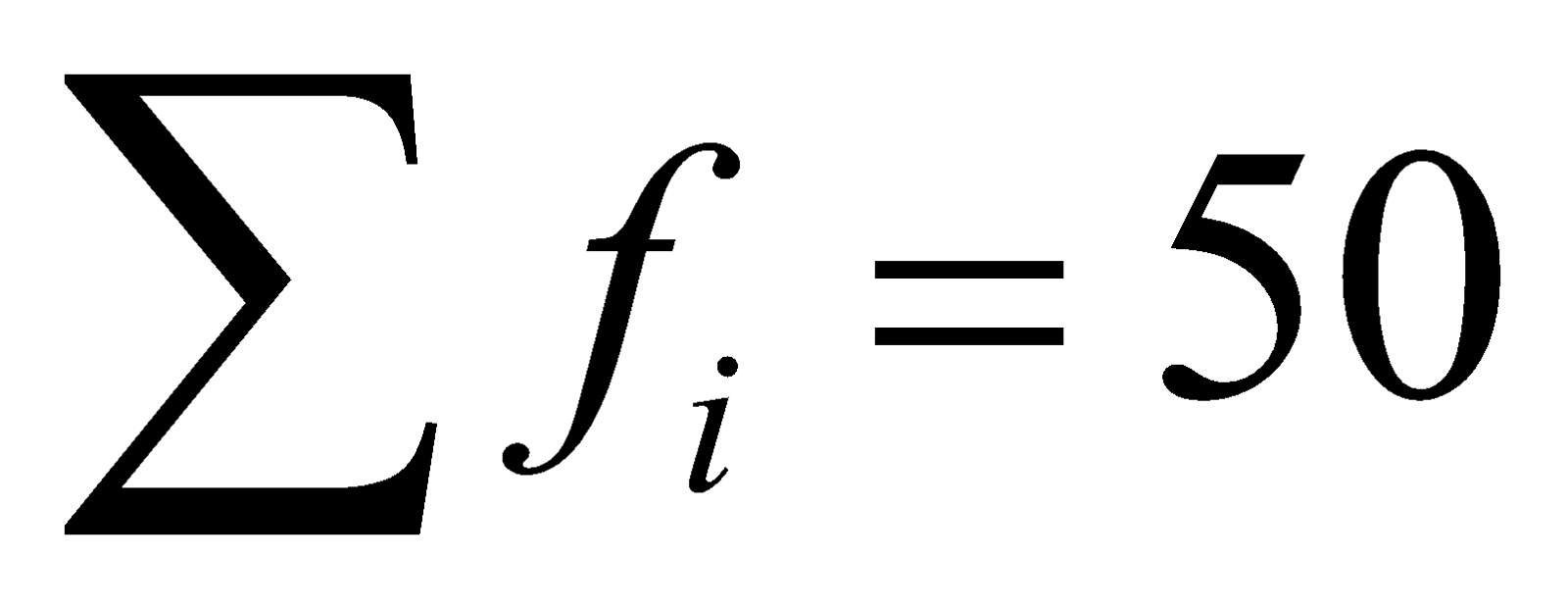 | 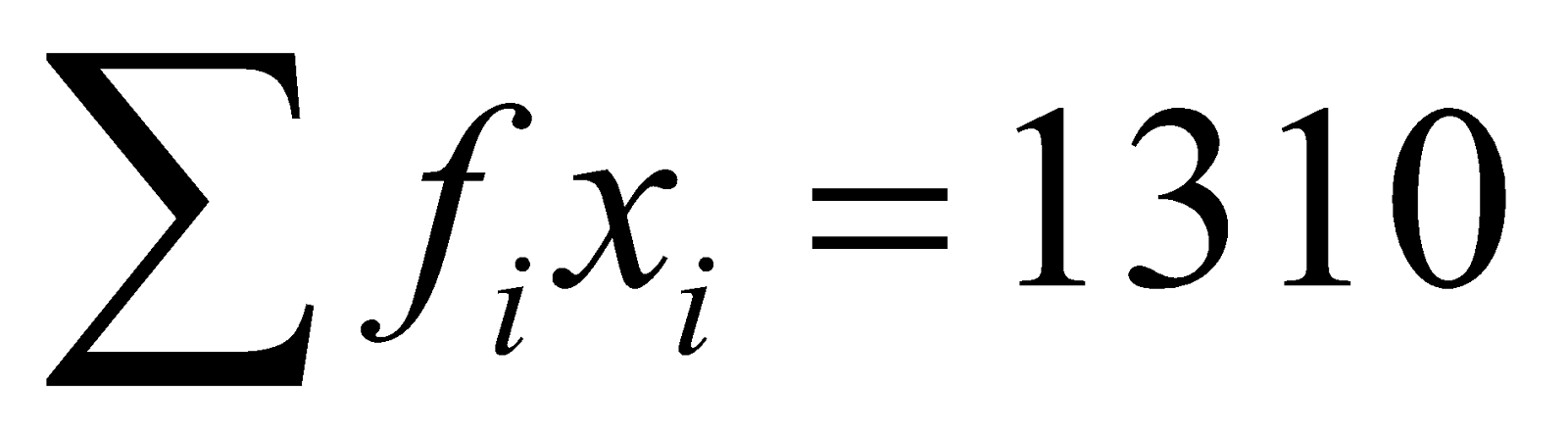 |
Now, we can find the mean of this data
Direct method,
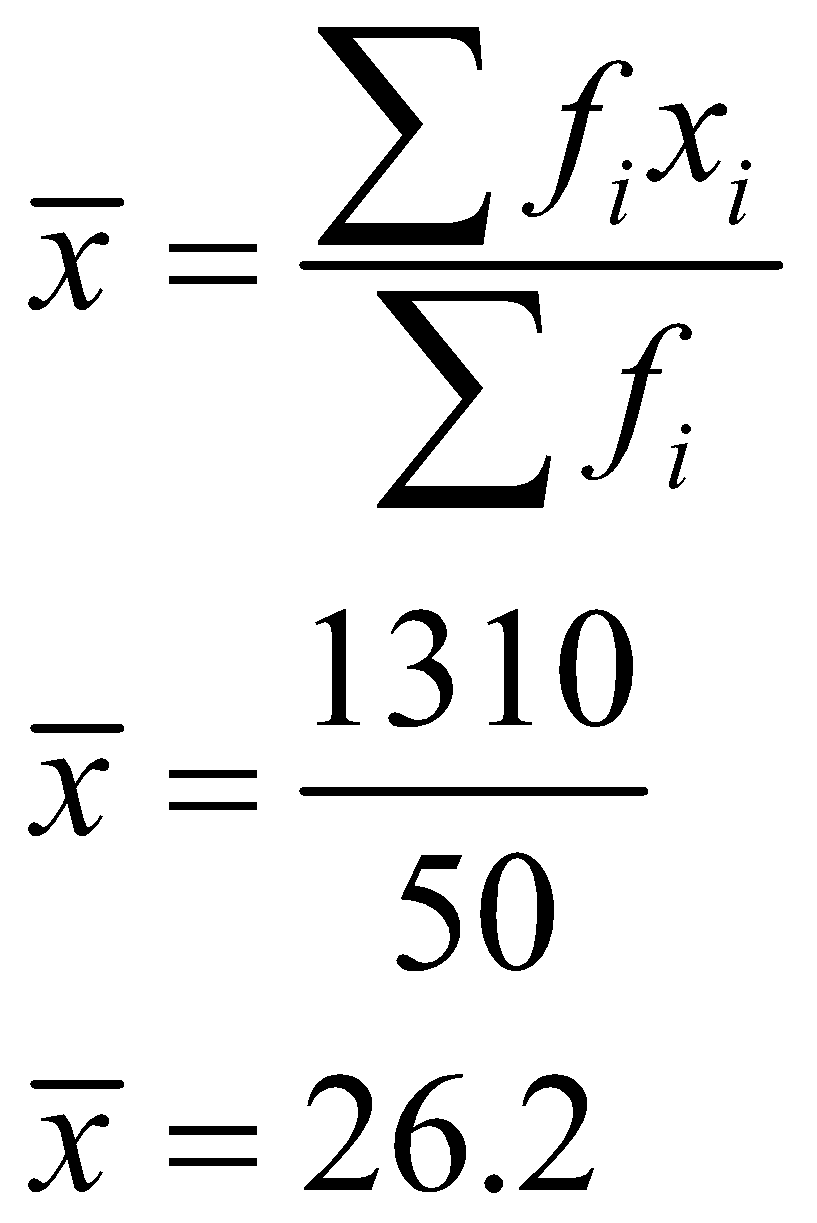
Assumed mean method,
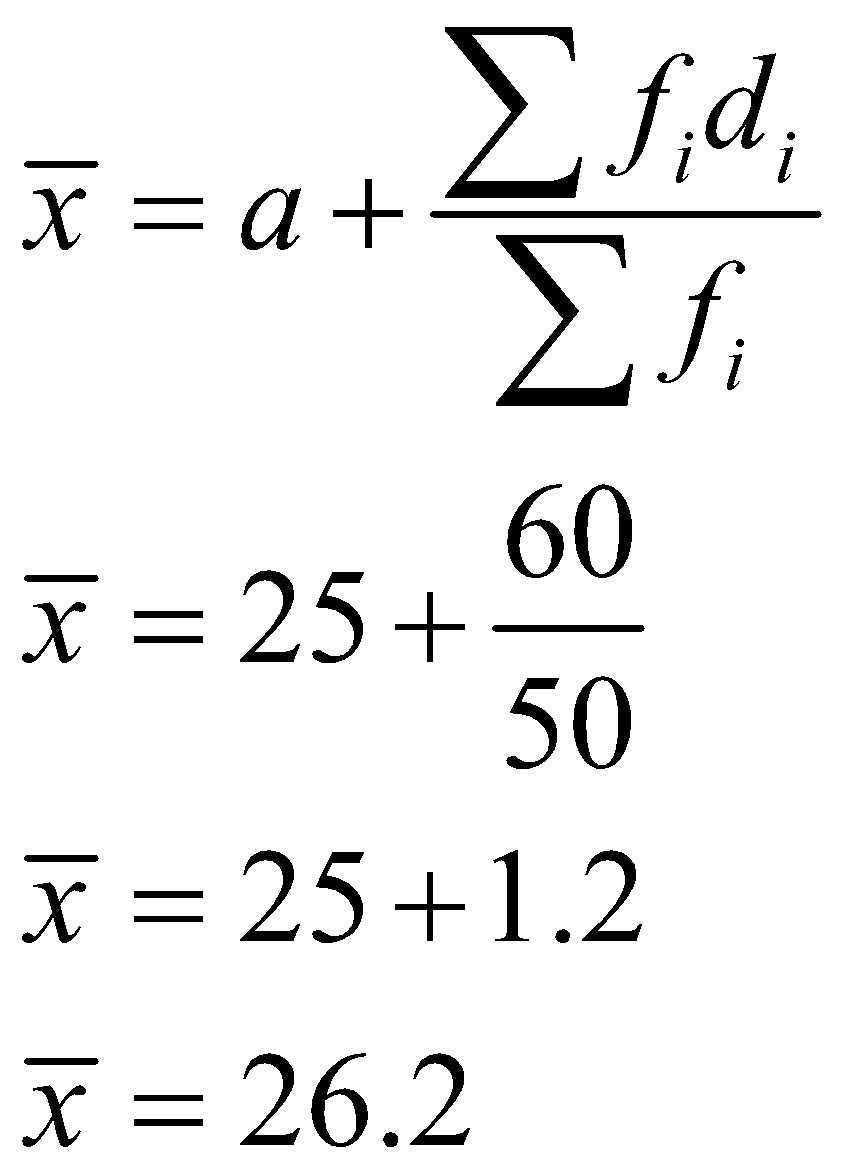
Step deviation method
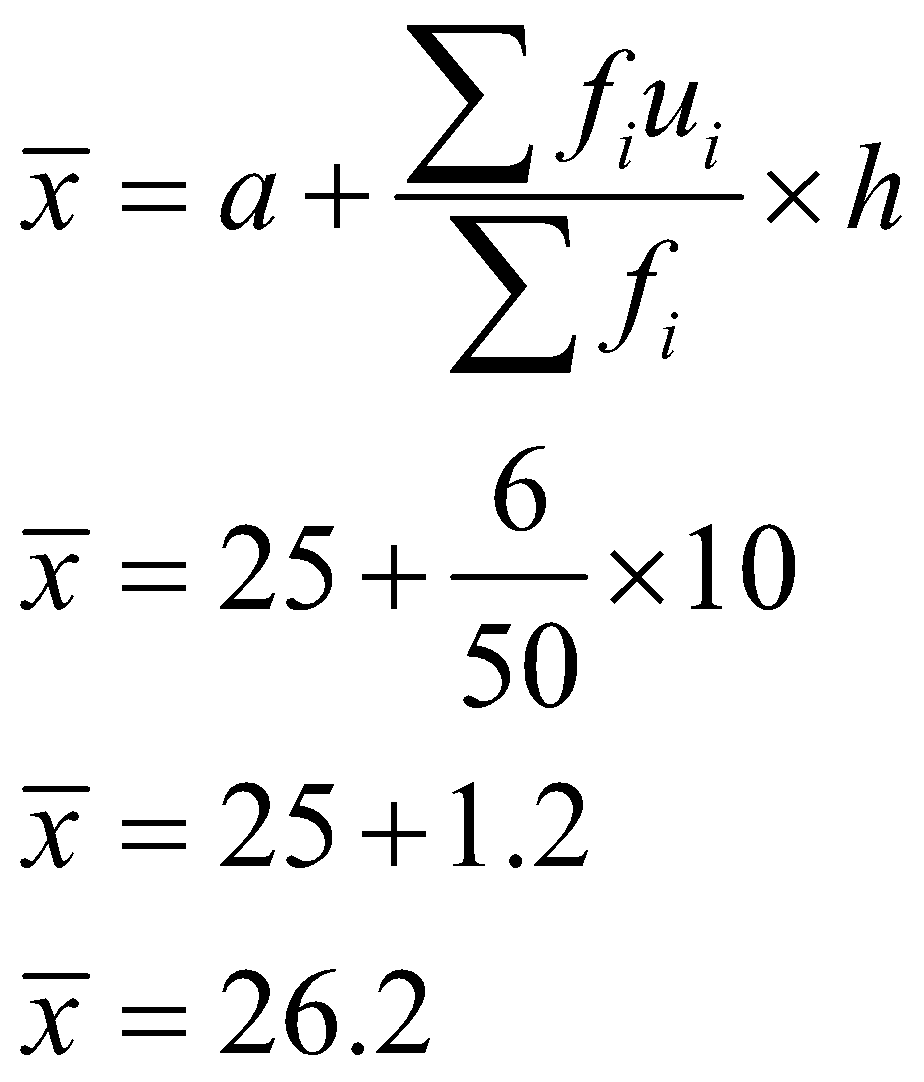
Hence, the mean of the given grouped data is 26.2, and we have verified the answer using all three methods.
Now for median using more than cumulative frequency distribution we have the following table,
| Class Intervals | Frequency | More Than | Cumulative Frequency |
| 0-10 | 6 | More than 0 | 50 |
| 10-20 | 10 | More than 10 | 44 |
| 20-30(Median Class) | 14() | More than 20 | 34 |
| 30-40 | 12 | More than 30 | 20() |
| 40-50 | 8 | More than 40 | 8 |
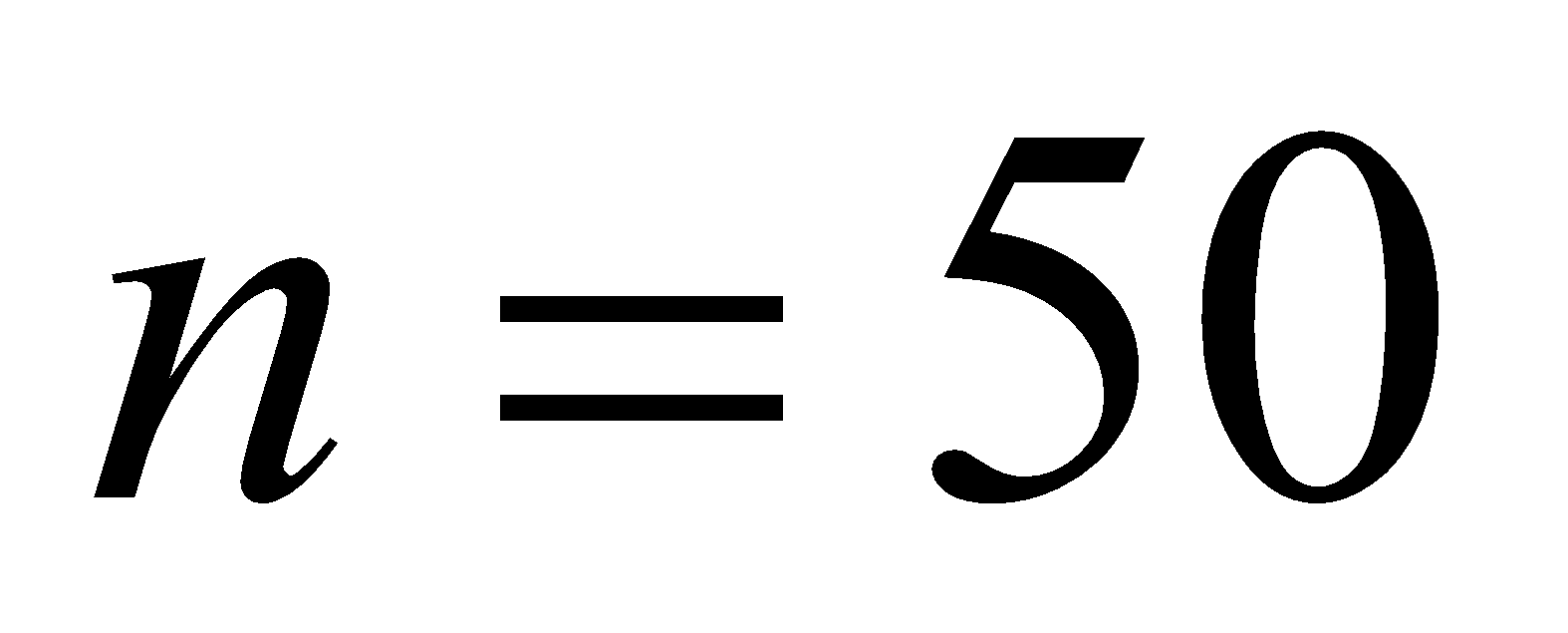 |
In the given table, we have the following values,
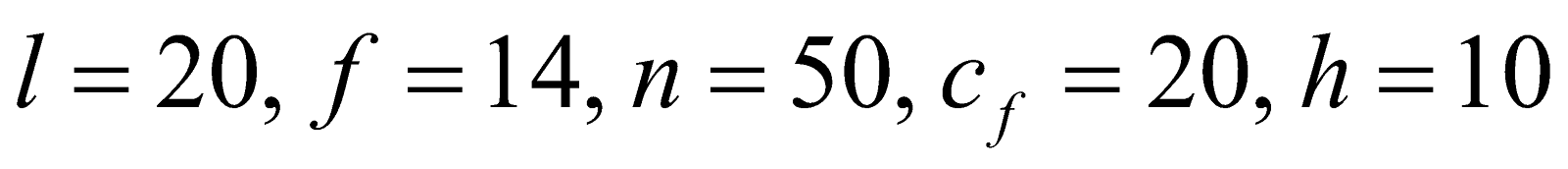
And the median is given by,
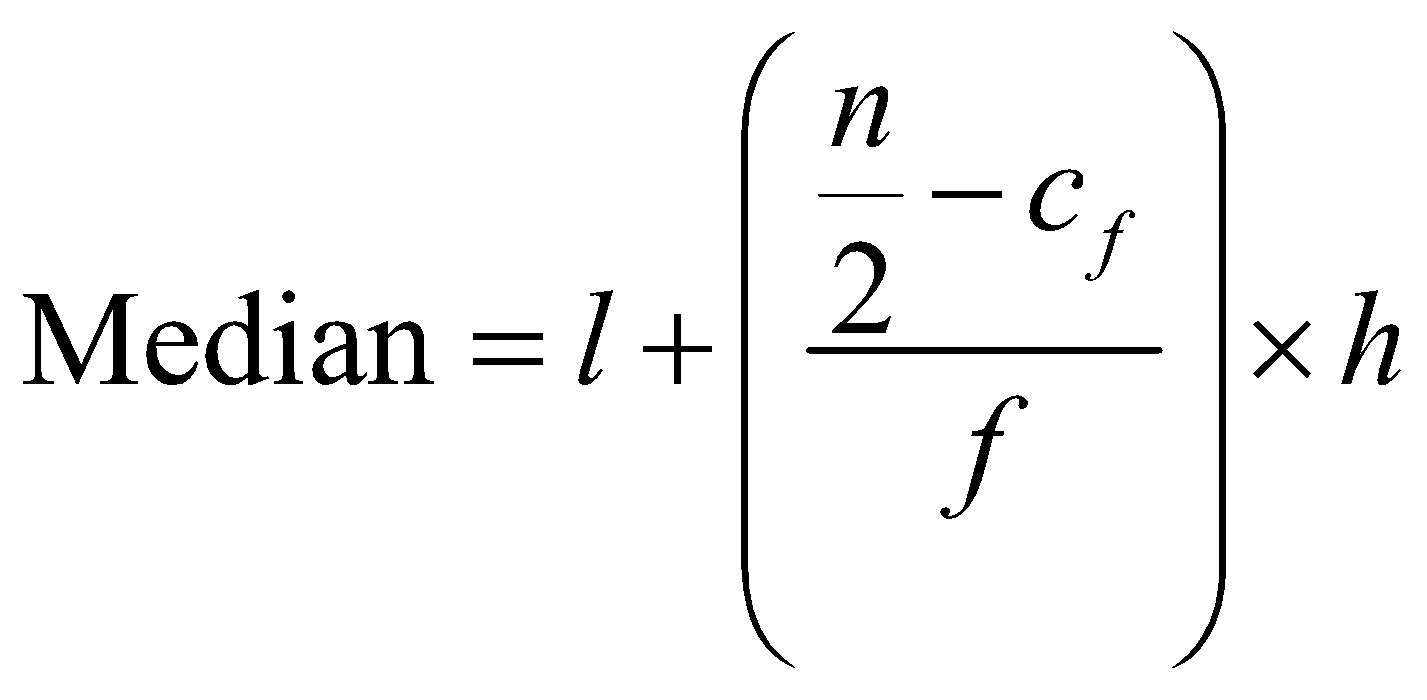
Substituting the values we have,
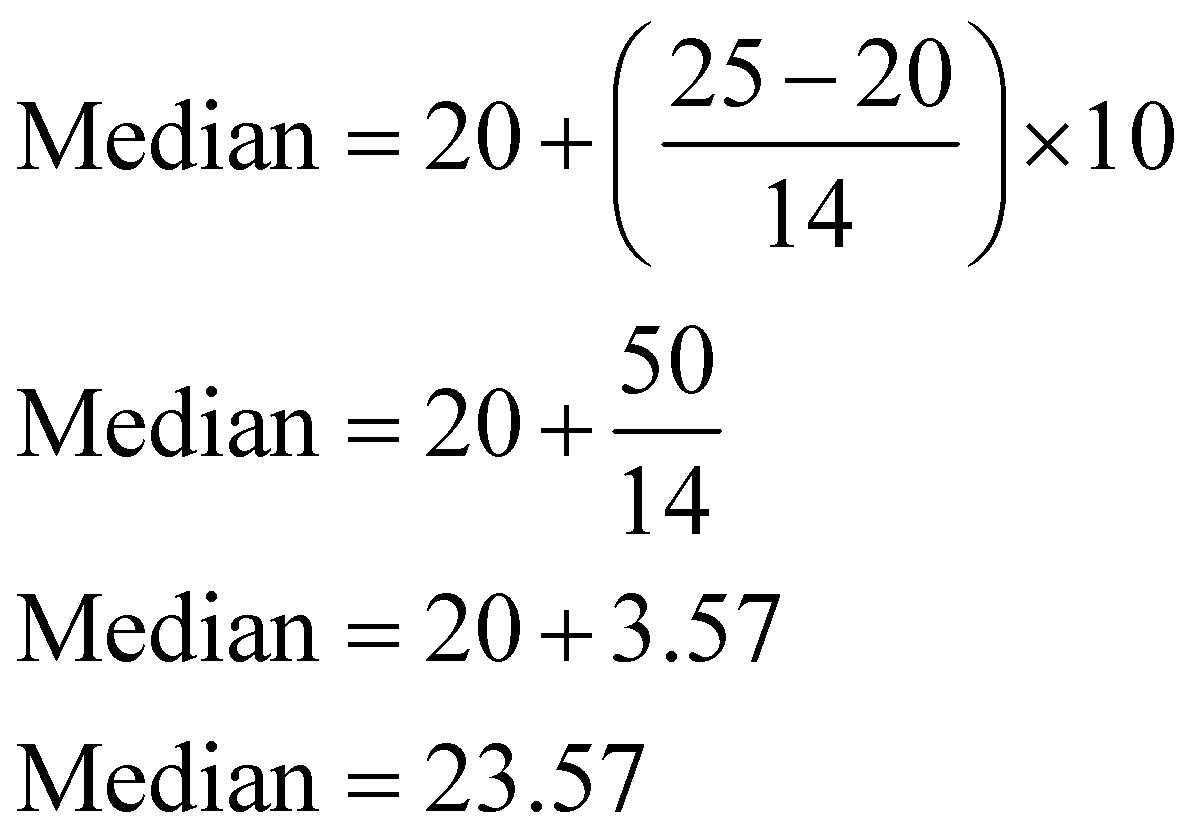
Hence, the median of the given grouped data is 23.57.
Looking for last minute help for your AP Statistics exam in May? Find an expert 1-on-1 online AP Statistics tutor from Wiingy and give your exam prep a boost!
FAQs
Q1. Why is the mean of a grouped data, grouped into class intervals slightly different from actual mean?
A1. Mean of a grouped data, grouped into class intervals, is calculated using class marks instead of the data points hence all the data points are approximated to the class mark of the class interval the data point belongs to. Thus, the mean is not accurately dependent on the data points but rather on class distribution.
Q2. What is variance?
A2. Variance is the measure of variation in each data point from the central tendency. Usually, the variance is calculated with respect to mean. The formula for the variance is, for ungrouped data
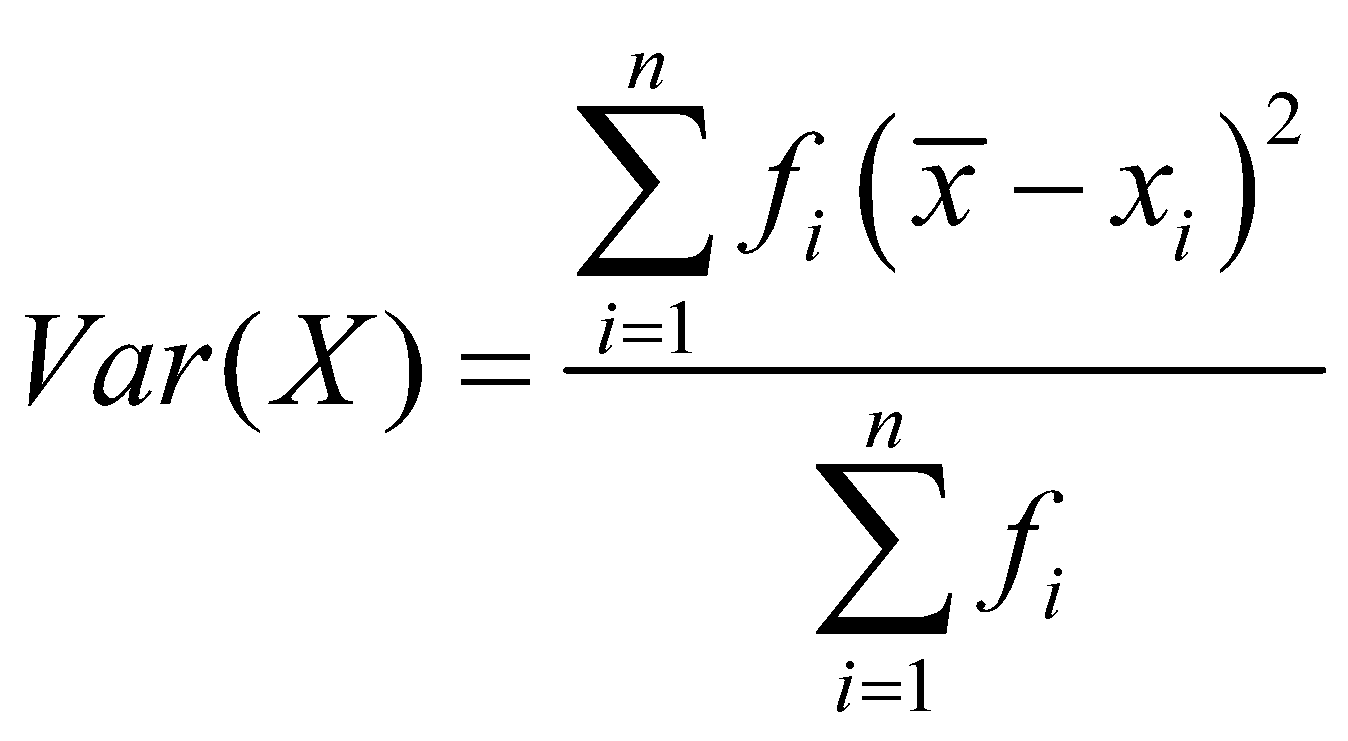
Where is the mean and have their standard meaning.
In grouped data the formula can be simplified to
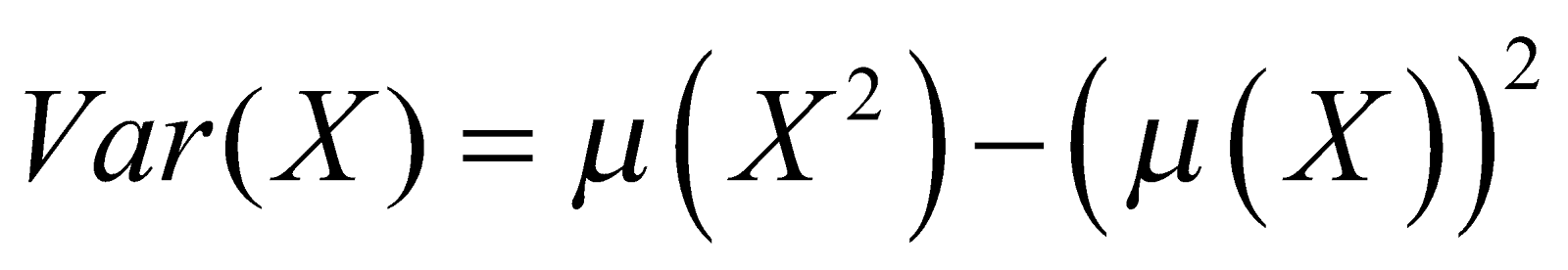
Where 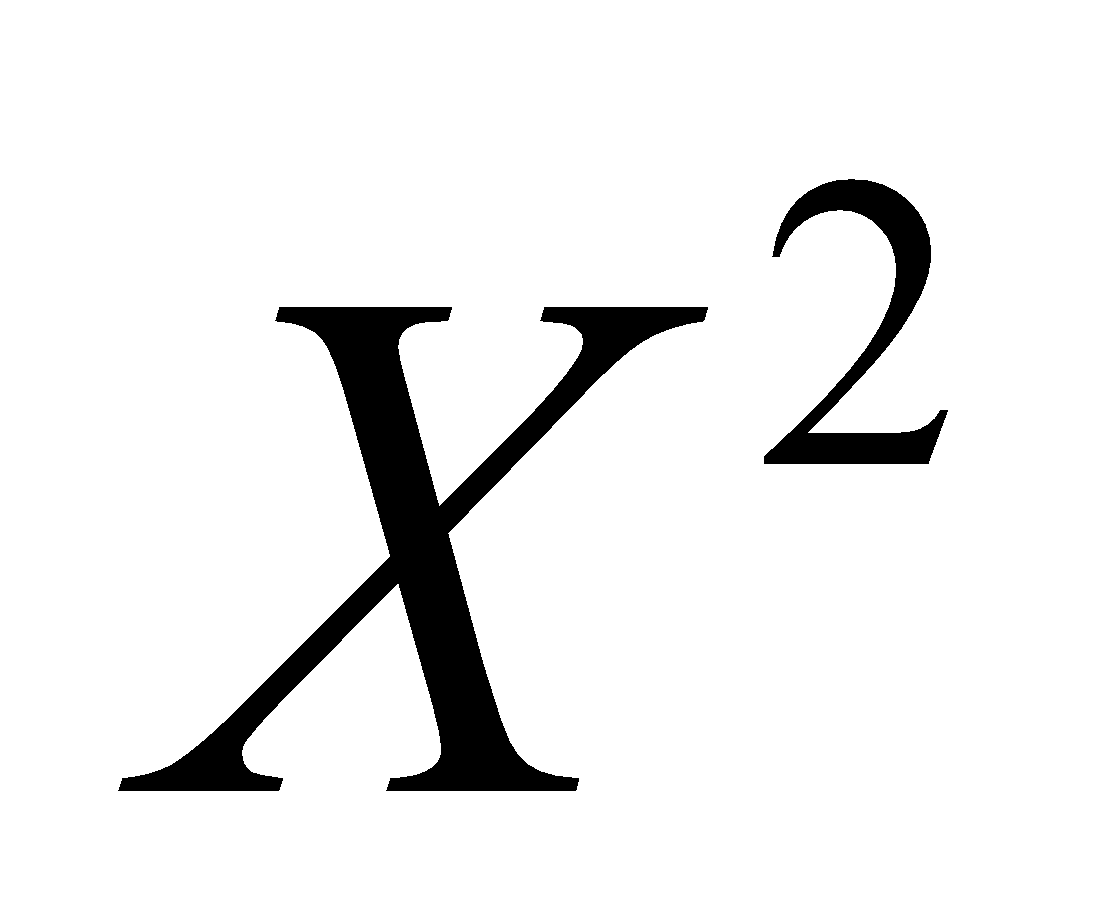
Q3. What is Empirical Relationship between the three central tendencies.
A3. The Empirical Relationship between the three central tendencies states that three times the Median is equal to the sum of Mode and twice the Mean.
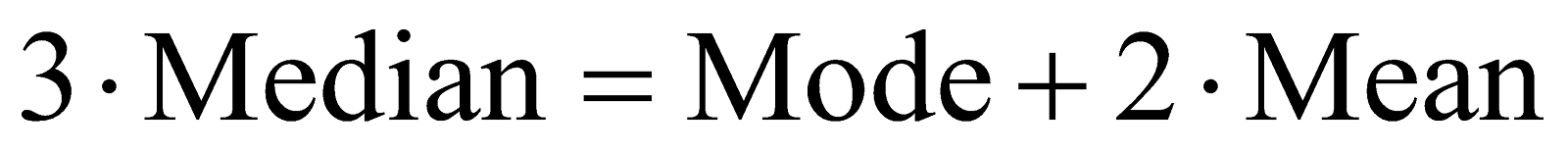
Q4. What are the three different types of means? What is the relation between them?
A4. There are three different types of mean
- Arithmetic Mean:
- Geometric Mean:
- Harmonic Mean:
The relation between the three means for two numbers and is given by,
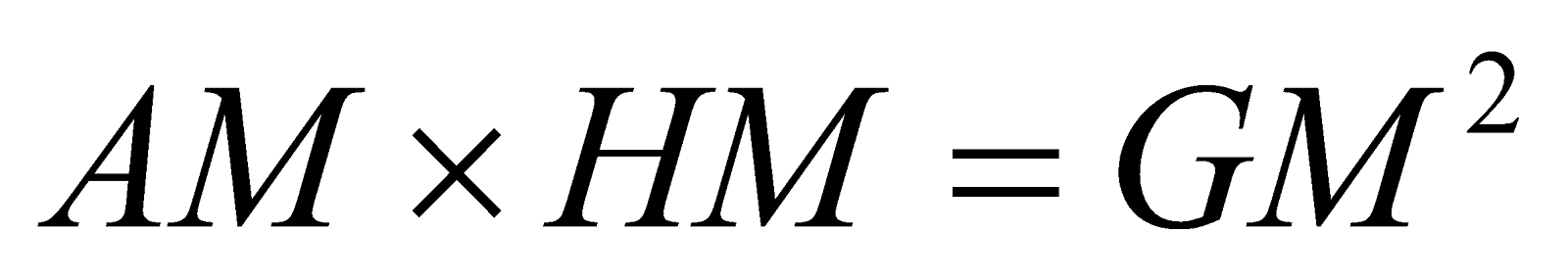
Q5. What are Ogive curves? How are ogive curves used to find the median?
A5. Ogive Curves are the graph plotted for a cumulative frequency distribution of a grouped data. Corresponding to the two types of cumulative frequency distribution, i.e., more than and less than, there are two types of ogive curves as well. Ogive curves are plotted by marking the data points on the x-axis and the cumulative frequencies on the y-axis.
Graphically, the point in the x-axis (Data points), where the more than and less than ogives intersect are the median.
References
Pham-Gia, T., & Hung, T. L. (2001). The mean and median absolute deviations. Mathematical and computer Modelling, 34(7-8), 921-936.
Lewis, J. R. (1993). Multipoint scales: Mean and median differences and observed significance levels. International Journal of Human‐Computer Interaction, 5(4), 383-392.

Mar 10, 2025
Was this helpful?